Notes on Section 4.4
机器学习的目标是发现“模式”,但是我们要求这个模式是general的
“将模型在训练数据上拟合的比在潜在分布中更接近的现象称为过拟合(overfitting), 用于对抗过拟合的技术称为正则化(regularization)”


独立同分布假设是指对于任意两个测试样本点,这两个样本点是互不干扰的,所以说也会在同一个逻辑框架下给出回答
但是事实上很多事物不符合或者轻微违反独立同分布假设,最典型的是具有时间依赖性/周期依赖性的一些事件

“在机器学习中,我们通常在评估几个候选模型后选择最终的模型。 这个过程叫做模型选择。 有时,需要进行比较的模型在本质上是完全不同的(比如,决策树与线性模型)。 又有时,我们需要比较不同的超参数设置下的同一类模型。”
“当训练数据稀缺时,我们甚至可能无法提供足够的数据来构成一个合适的验证集。 这个问题的一个流行的解决方案是采用折交叉验证。 这里,原始训练数据被分成个不重叠的子集。 然后执行次模型训练和验证,每次在个子集上进行训练, 并在剩余的一个子集(在该轮中没有用于训练的子集)上进行验证。 最后,通过对次实验的结果取平均来估计训练和验证误差。”
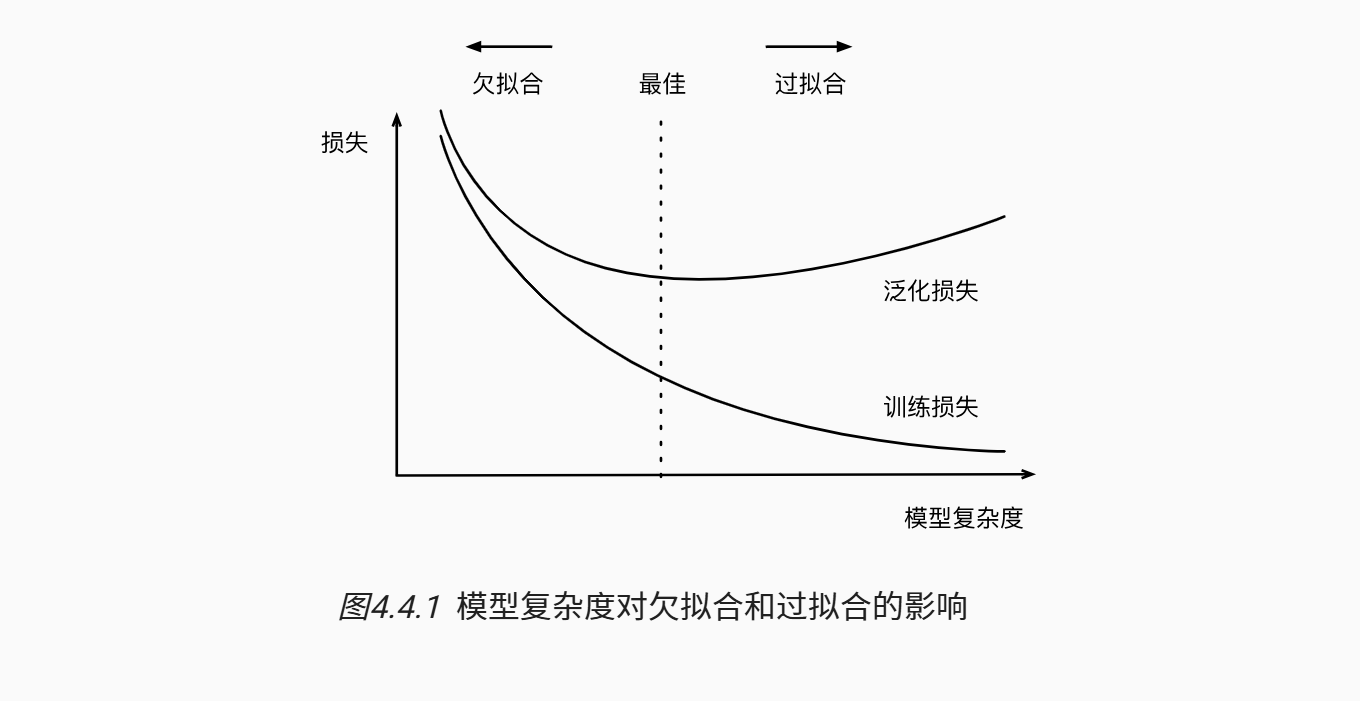
也即我们需要找到泛化损失最低点
- Title: Notes on Section 4.4
- Author: bobown_yao
- Created at : 2025-12-24 00:00:00
- Updated at : 2026-01-19 13:37:57
- Link: https://bobownyao.github.io/2025/12/24/Notes-on-Section-4-4/
- License: All Rights Reserved © bobown_yao