Notes on Section 8.2
序列数据处理问题中比较重要的一个部分是对序列化文本的处理
对于一个文本数据,我们可以对其进行词源化拆分或者是字符化拆分
我们先加载一个文本
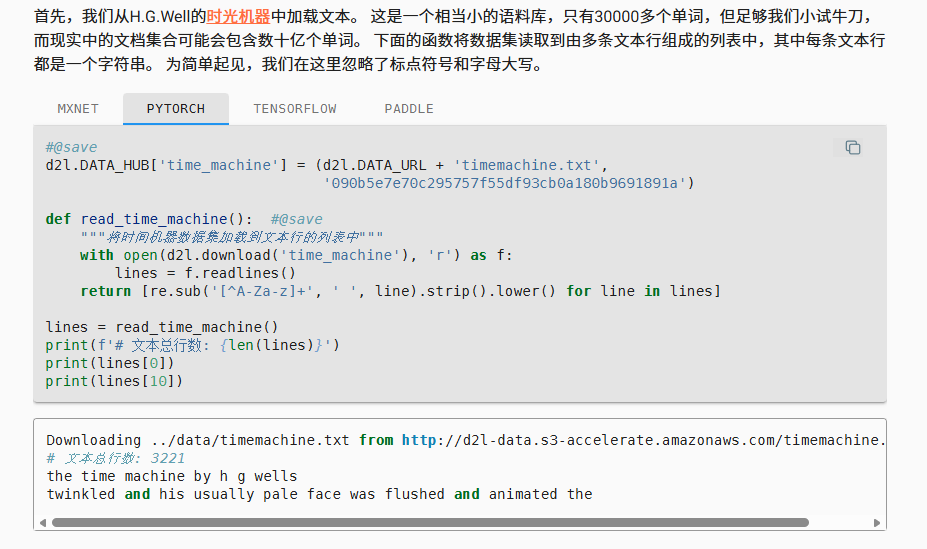
return [re.sub(‘[^A-Za-z]+’, ‘ ‘, line).strip().lower() for line in lines]
注意到这一行,这一行进行的操作包括去除所有的标点符号,前后空白字符,全文本小写化
我们设置两种拆分token的模式,分别是按词汇(每行使用split)或者是按字符(每行list化)


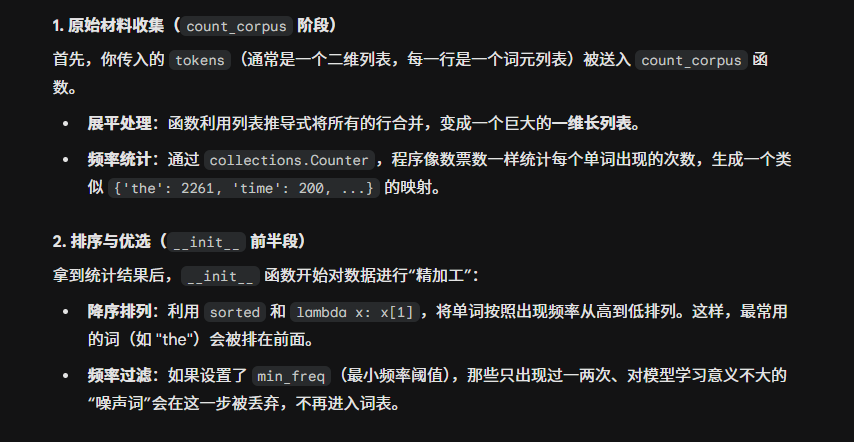
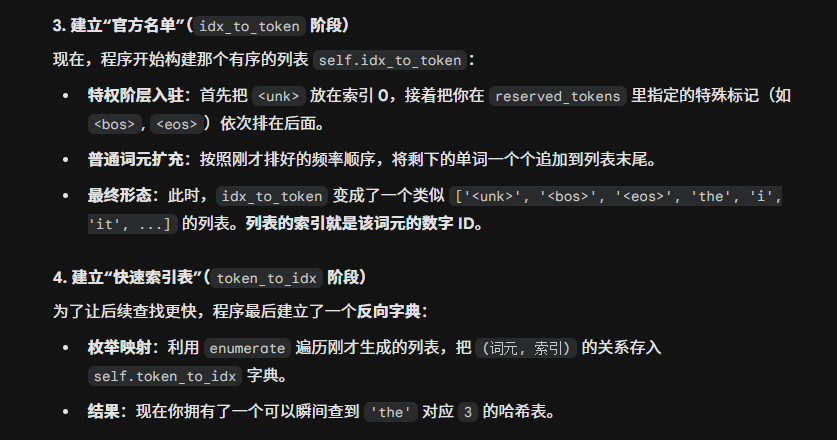
接下来一步是对单词进行量化,做法是将一个单词映射到一个数字索引。这个索引在训练的时候使用,在模型测试或者是正式跑的时候也是一个映射库。这个库由一般单词和特殊词元组成,几个特殊词元分别是未知词元unknown
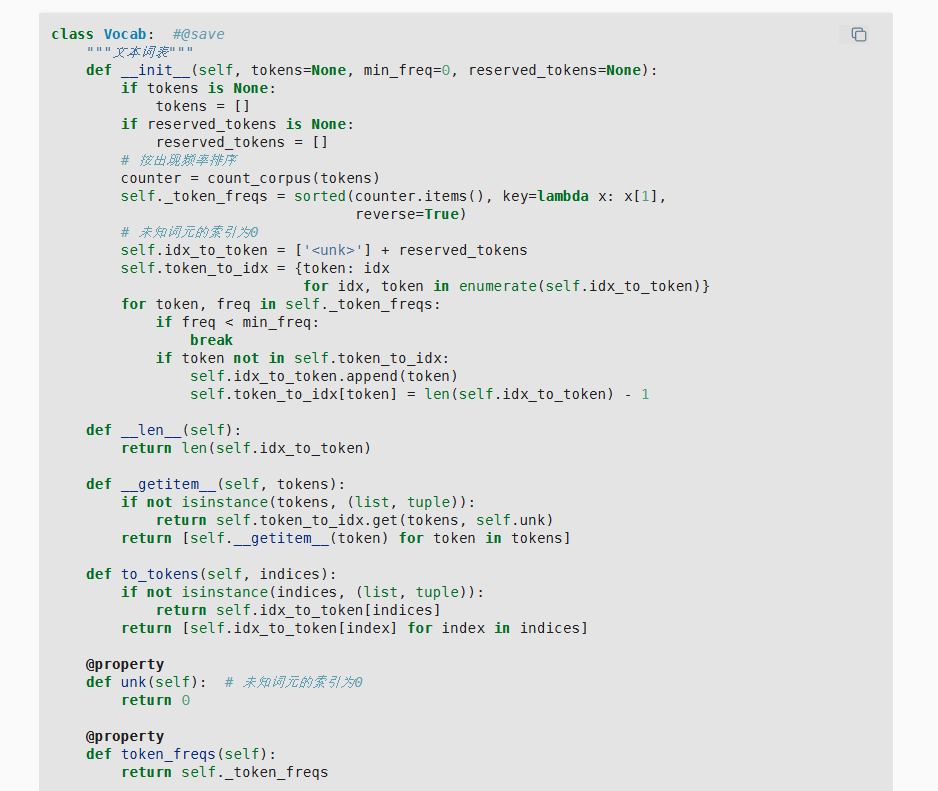

我们调用vocab = Vocab(tokens) 建立这个词库,以下表述了数据流动的方式
然后我们可以用vocab[“word”]或者的形式调用这个库
这对应了其中的getitem内置函数


结构化之后的效果如下
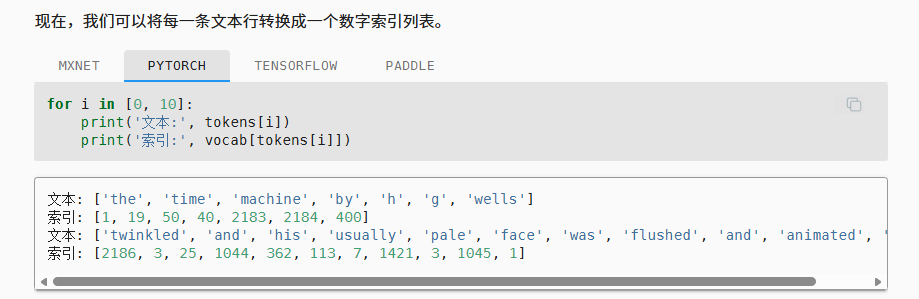
以下我们进行一个整合
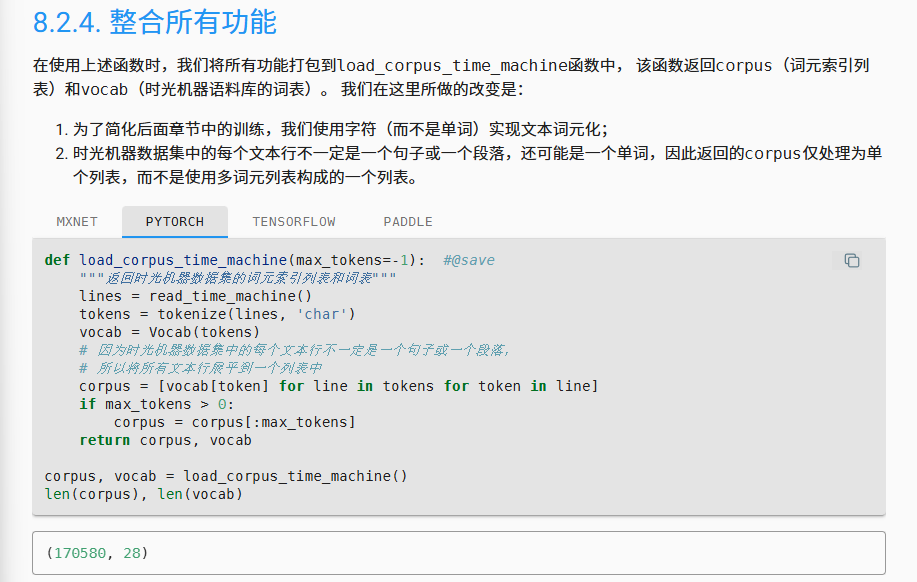
在这个整合中,我们使用了字符作为分划对象,也就是说这个数据的粒度会比较小,这里的考虑是我们的词库会很小,这个在参数数量上会有简省,同时我们预期会提升robust,因为字符级说明其理论上可以处理任何单词,更好的处理一些比较生僻的单词。(然后这个处理的时候会读入空格,而不是像单词那样省略空格)
不过也会引入一些问题,一个是训练网络的深度和训练需要的周期应该会增长,因为我们需要教会模型拼写先,然后才是处理文本词汇之间的一些关系。
- Title: Notes on Section 8.2
- Author: bobown_yao
- Created at : 2026-02-06 00:00:00
- Updated at : 2026-03-08 19:46:44
- Link: https://bobownyao.github.io/2026/02/06/Notes-on-Section-8-2/
- License: All Rights Reserved © bobown_yao