Notes on Section 9.1
传统的RNN的训练过程中,梯度消失和爆炸是一个问题。以下介绍的一些策略有利于缓解这个现象,以达到训练模型的效果
首先是概念:门控(Gating),即根据特定的条件(信号),来决定是否允许信息、电流或计算流通过。

这也就意味着,模型可以对文本部分的重要性进行学习,变相提升了专注度和输出文本的连续性。
这也就是门控循环单元(gated recurrent unit, GRU)
在这个框架中有重置门(reset gate)和更新门(update gate)
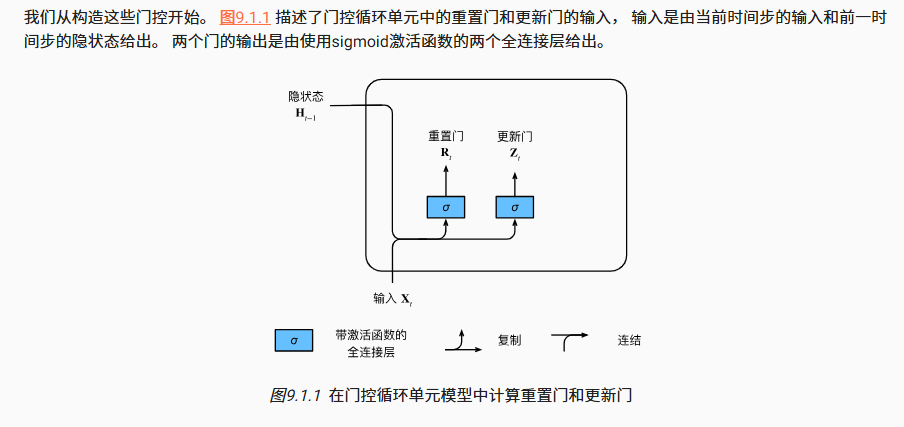
对应的数学转换方式如下

这里一个特征就是,我们使用了sigmoid函数,这个函数把数值压缩到0-1,这对于门控判断什么信息可以流通至关重要
这里的W_xr/z也是整个过程中统一的参数,这个和计算H的那套参数的设置原理是一样的
R/Z矩阵的数据流向略有区别,我们先来看R矩阵的使用

这里R的作用就是,决定有多少的过去信息(来自上一个H)流入当前的待选隐状态(通过R和H的hadamard积体现)。Tanh函数在这里保证了输出隐藏态H的一致性
随后使用Z计算合并

这里将上一个隐状态和候选隐状态凸组合,得到了当前的隐状态
整个流程如下
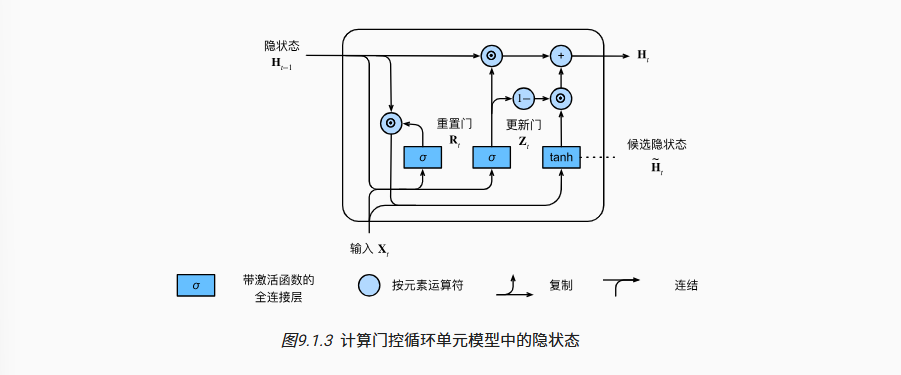
总之,门控循环单元具有以下两个显著特征:
- 重置门有助于捕获序列中的短期依赖关系;
- 更新门有助于捕获序列中的长期依赖关系。
GRU主要解决了梯度消失的问题,因为在反向传播的时候

- Title: Notes on Section 9.1
- Author: bobown_yao
- Created at : 2026-03-01 00:00:00
- Updated at : 2026-03-08 19:46:44
- Link: https://bobownyao.github.io/2026/03/01/Notes-on-Section-9-1/
- License: All Rights Reserved © bobown_yao