Notes on Section 2.3
这一部分,主要说的就是线性代数,其实没什么好说的,不过还是有一些对于深度学习的特化(额也有可能是我还没学到的线代部分)
首先一个点是向量的长度和维度是一个概念(毕竟是一维的,如果要从结构上使向量的维度不平凡好像就是这样定义)
降维操作
这个主要是通过一些统计相关的函数实现,比如求和,求平均数等函数,这些函数内置于pandas/numpy
需要注意的是!!!默认调用这些降维函数时确实会发生降维,比如
x = np.arange(4)
x, x.sum()
表示为 (array([0., 1., 2., 3.]), array(6.))
其中我们发现6.已经是一个标量了
当然我们可以通过一些操作保留维度(那么最小的那个维度对应的组里面都是单独的元素)
sum_A = A.sum(axis=1, keepdims=True)
既这个keepdims 输出效果如下
array([[ 6.],
[22.],
[38.],
[54.],
[70.]])
点积
这个就是矩阵的乘法,向量-向量/矩阵-向量同理,不过需要注意的是两个向量x,y的乘法实际是xTy,因为本部分默认所有的向量都是列向量的形式
另外就是Hadamard积,那个是元素对元素的积,应该和上述的积加以区分
范数(norm),是一个常用的运算符。范数体现的是一个向量整体性分量的大小,
$$||\mathbf{x}||_p = \left( \sum_{i=1}^n |x_i|^p \right)^{1/p}$$
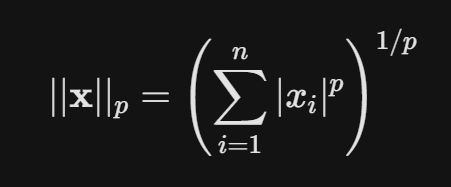
我们可以想象一个n维空间,那么一个长度为n的向量就代表了这个空间中的一个坐标,这时候我们想要计算原点到这个坐标的路径长度(当然这个路径的模式和范数L下标有关)
我们有L1是曼哈顿距离
L2是欧几里得距离
L3及以上,我们可以理解为是越长的那个分量约占据主导(不过这个范数本身还是线性的)
因为范数运算将整个向量完全降维为标量,所以我们可以比较不同维度向量的范数,这是可行的


- Title: Notes on Section 2.3
- Author: bobown_yao
- Created at : 2025-11-24 00:00:00
- Updated at : 2026-01-17 16:18:07
- Link: https://bobownyao.github.io/2025/11/24/Notes-on-Section-2-3/
- License: All Rights Reserved © bobown_yao