Notes on Section 3.1
所以核心思想就是找到最佳权重使得偏移量最小
然后这个线性方程组的拟合是可以有解析解的

但是这个用处不是很大(当然知道如何推导这个还是比较有意义的),因为大部分拟合函数都不是线性的,参数对输出结果的影响也不一定是线性的
所以这里引入了一个随机梯度下降(gradient descent)的概念,可以在无法得到有效解析解的情况下训练模型
“梯度下降最简单的用法是计算损失函数(数据集中所有样本的损失均值) 关于模型参数的导数(在这里也可以称为梯度)。 但实际中的执行可能会非常慢:因为在每一次更新参数之前,我们必须遍历整个数据集。 因此,我们通常会在每次需要计算更新的时候随机抽取一小批样本, 这种变体叫做小批量随机梯度下降(minibatch stochastic gradient descent)。”
注意,这里的随机抽取的对象是样本,也就是说,我们有很多的训练数据,但是我们不会同一时间全部使用他们,而是在一轮训练中只抽样式的选择一些数据点。但是,对于参数来说,是的,我们会计算整体梯度并更新每一个参数。
以下是一个简要的比较


另外补充以下符号的含义,权当复习了(其实就是主播忘记了qwq
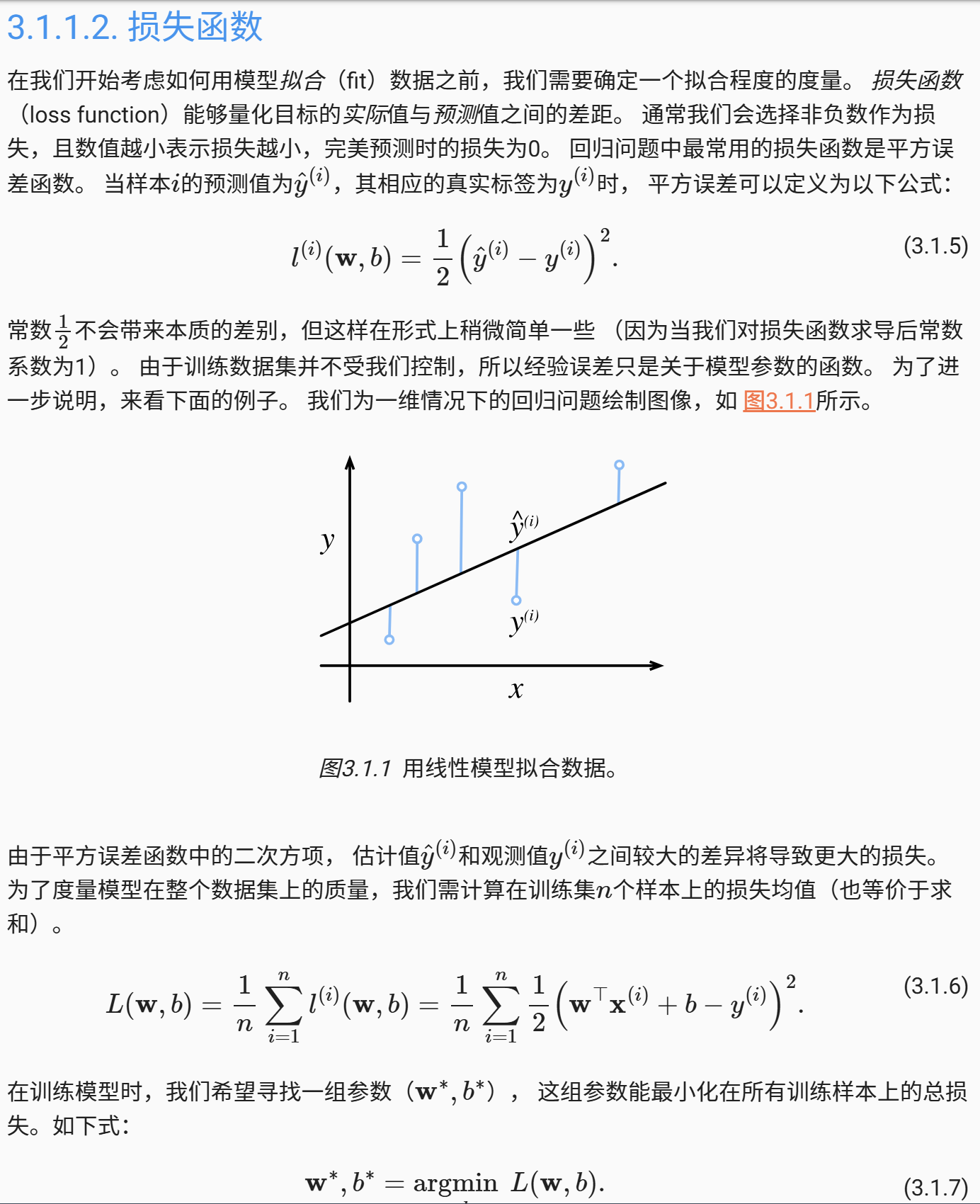
对于w,b两个参数分别的更新,可以更为详细的写为以下
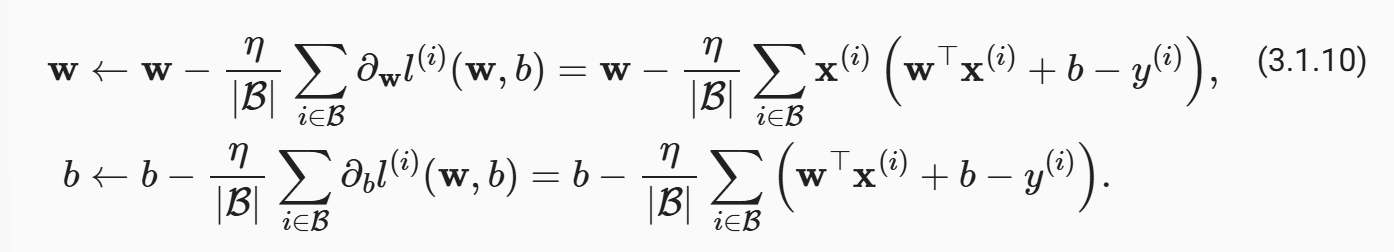
这个解析式也可以推一下,挺有意思的
给一个w的范例,另一个是同理的

3.1.2矢量化加速
这个就是一个概念性的东西(基于numpy库的一些优化)

反正就是用numpy的张量计算比for循环要快(还有比python的循环慢的东西吗。。。)
3.1.3正态分布与平方损失
首先我们有正态分布的表达式如下
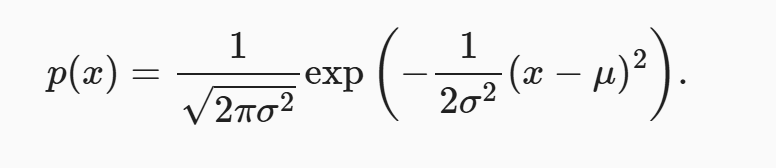
这里有有一个非常有意思的现象
就是虽然我们是用np.arange创建的x
但是在pytorch框架下,这个参数很可能被认为是一个张量
于是当使用绘图函数(一般接受的是numpy数组输入)的时候,我们需要指定并转换,这也就是其中asnumpy的作用

这里稍微提一嘴这个,这个也就是我们修正函数的依据(也就是为什么最小化均方差损失是正确的函数拟合方向)

这里的两个观点都是对的哦,我觉得对于增进我的理解比较有帮助

这个没啥好说的,摆烂了
“虽然可能受到鸟类的启发,但几个世纪以来,鸟类学并不是航空创新的主要驱动力。 同样地,如今在深度学习中的灵感同样或更多地来自数学、统计学和计算机科学。”
- Title: Notes on Section 3.1
- Author: bobown_yao
- Created at : 2025-11-29 00:00:00
- Updated at : 2026-01-17 16:18:07
- Link: https://bobownyao.github.io/2025/11/29/Notes-on-Section-3-1/
- License: All Rights Reserved © bobown_yao