Notes on Section 3.2
“在这一节中,我们将从零开始实现整个方法, 包括数据流水线、模型、损失函数和小批量随机梯度下降优化器。 虽然现代的深度学习框架几乎可以自动化地进行所有这些工作,但从零开始实现可以确保我们真正知道自己在做什么。”
首先是生成数据,这里的X也就是样本空间其实也是正态分布随机生成的,所以其实每次调用的时候都不一样(当然实际使用的时候肯定是以一个固定的数据集)
Y也就是我们处理得到的输入了(注意这里使用了y.reshape((-1, 1)),-1其实是占位符,pytorch会自动计算这一部分的大小,这一步的操作是保证y是一个列向量的形式)
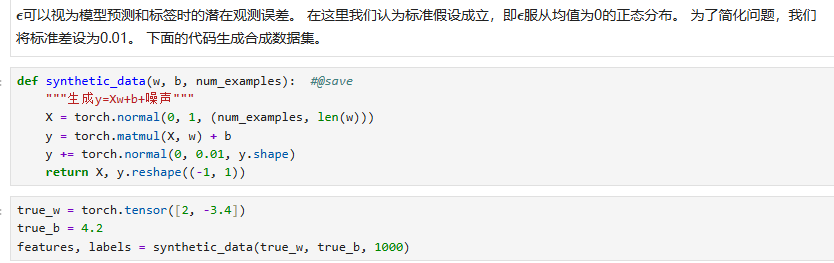
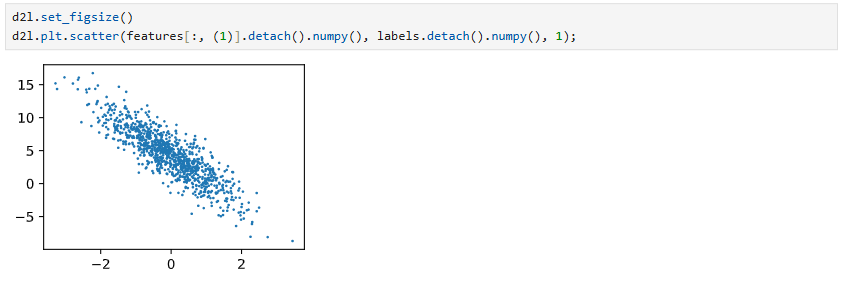
同时我们可以实现一下可视化(然后注意到d2l是深度整合matplotlib的)
这边同时解释一些操作函数

那么我们接下来就可以开始读取数据了
这里我们根据随机梯度下降的算法思想,打乱样本并且分批次选取
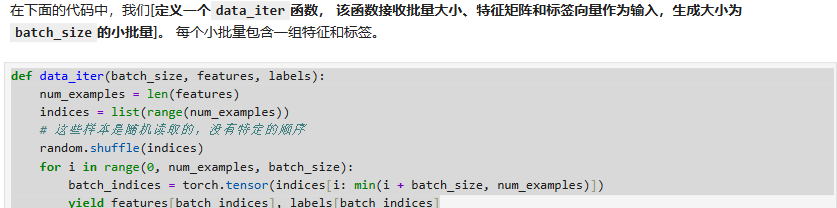
注意到这里实际上遍历了每个样本点(相当于打乱样本点后用batchsize分划打包,然后一份份给出去算梯度)
然后我们注意到这个yield指令,这个是有别于return的,直观上看,其在执行后不会关闭函数

一个包含 yield 的函数在被调用时,会创建一个特殊的本地对象,即生成器对象(Generator Object),这个对象内部保存了函数执行的完整状态和上下文,包括上一次的断点。
数据处理和选取这块结束之后,我们还需要初始化一下权重(w,b)

接下来我们分别定义模型(也就是参数和权重的作用关系)/损失函数(一般就是平方损失函数)/优化算法
这里我打算学习一下两个pytorch计算梯度的重要组成,也就是.grad属性 和 .backward()函数
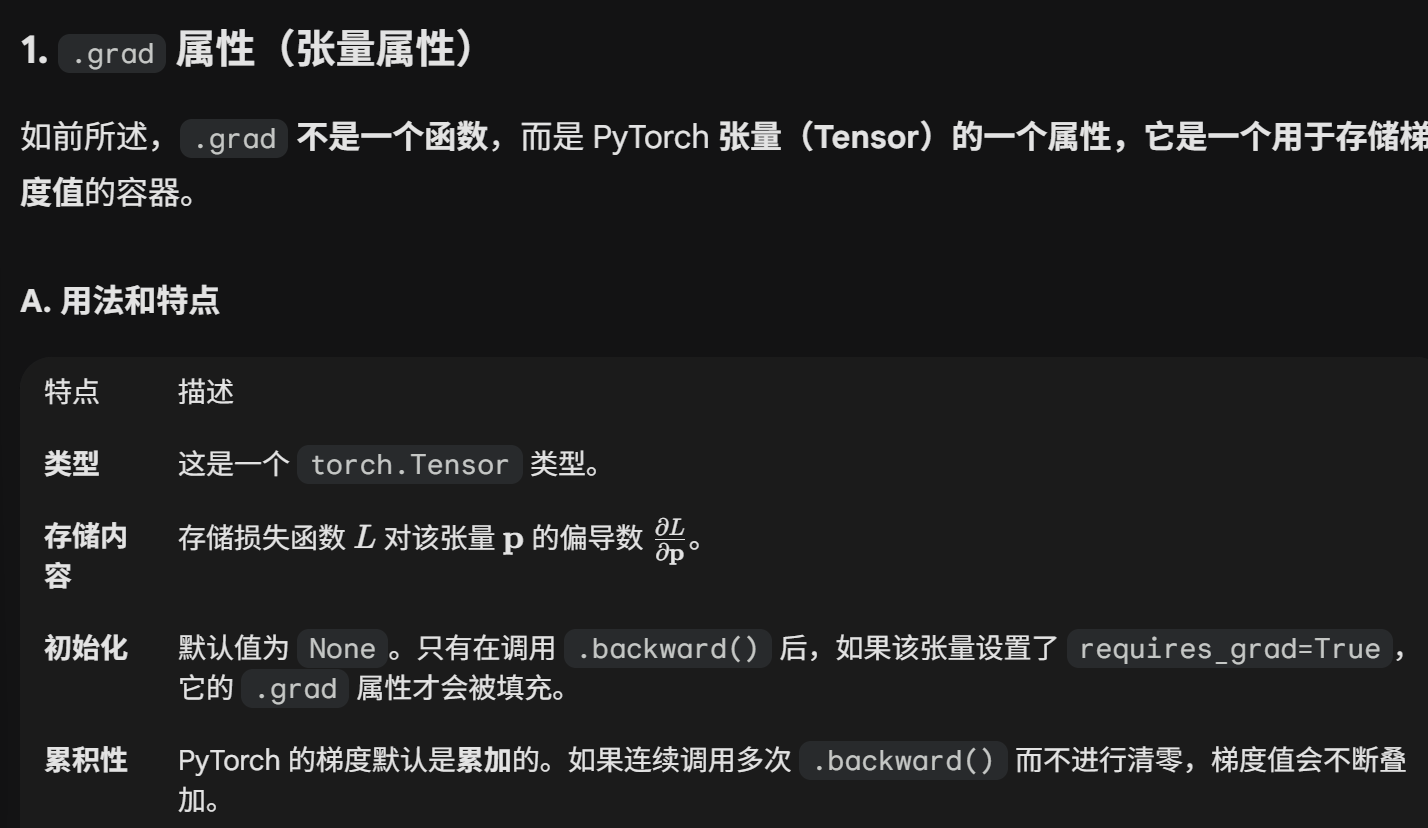
这个累加性是值得注意的,这解释了为什么梯度提取之后需要清零
假设 w 已经被初始化并设置 requires_grad=True
在反向传播之前
print(w.grad) # 输出: None
# 经过 L.backward() 之后
print(w.grad) # 输出: tensor([[-0.1234], [0.5678]]) (这是计算得到的梯度值)
在优化器中,使用后必须清零
w.grad.zero_()
print(w.grad) # 输出: tensor([[0.], [0.]]) 非空但是为0向量
以下则是关于.backward()

这里的L即我们要求的损失函数,其是变量和权重等等参数复合成的复杂函数。Pytorch在自动积分的时候,会构建DAG理解这样一个函数,其中被指明需要计算梯度的变量也会被计算(然后就可以用.grad 读取了)
- Title: Notes on Section 3.2
- Author: bobown_yao
- Created at : 2025-12-01 00:00:00
- Updated at : 2026-01-17 16:18:07
- Link: https://bobownyao.github.io/2025/12/01/Notes-on-Section-3-2/
- License: All Rights Reserved © bobown_yao