Notes on Section 3.3
我们可以使用d2l内置的函数生成样本,注意这个函数生成样本点是自动含有噪音的
详情可以参考下面的def
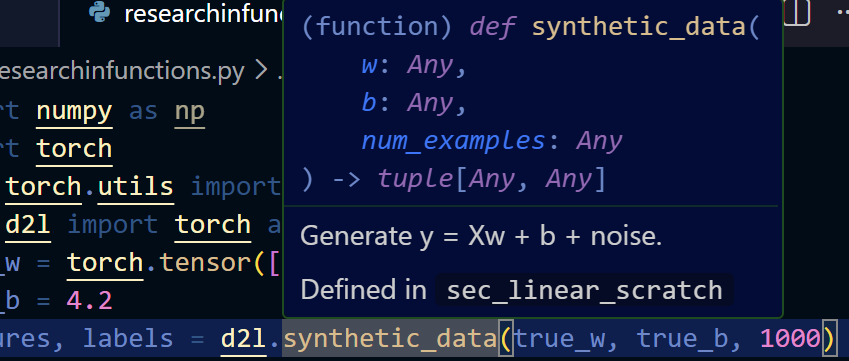
生成数据之后我们创建一个迭代器来处理我们的数据

这里面涉及了两个pytorch函数
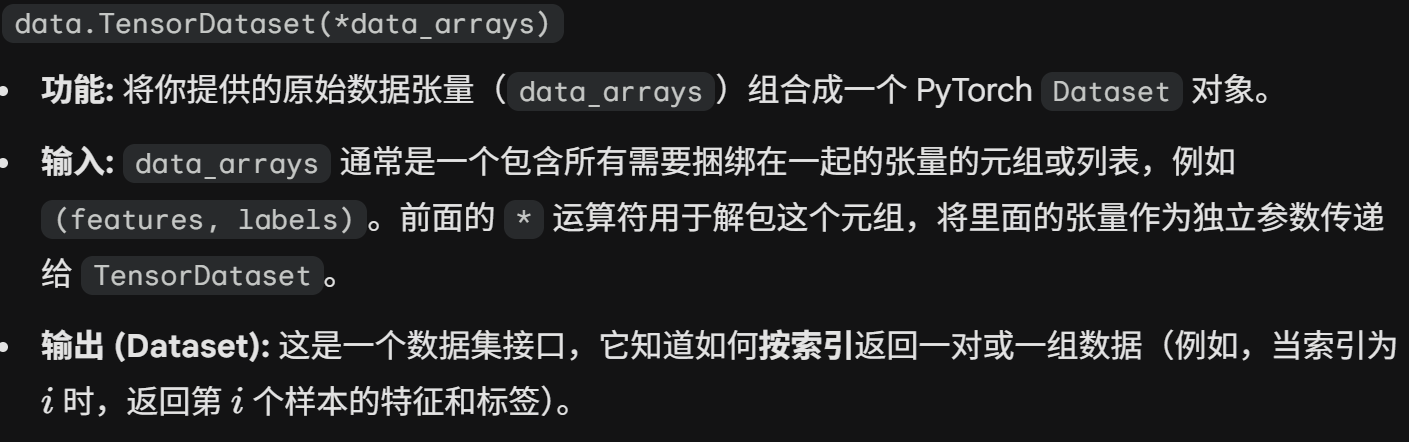
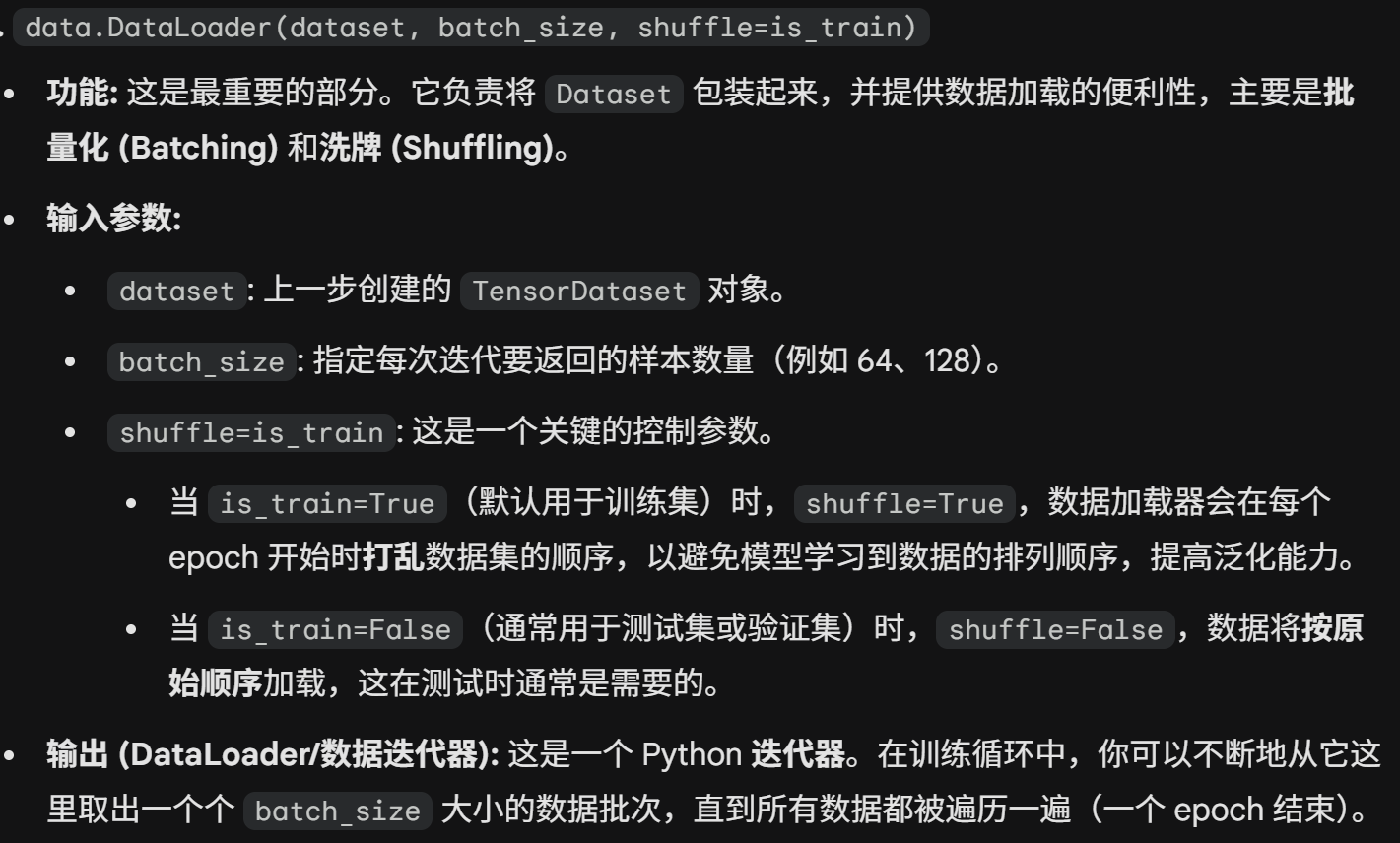
这里生成的data_iter虽然是一个迭代器,可以用for/in结构读取,但是本身不是一个python的基础迭代器类型,可以通过iter(data_iter)转换成基础迭代器的(比如list/tuple/str/range这些可迭代对象,在使用for in 的时候程序也是会默认转换成iter类型再执行循环的)
深度学习的模型构建可以使用内建的框架
主要由nn(neuron network)这个库实现

也就是sequential包含linear等等计算层,形成一个计算链
接下来就可以初始化参数了

注意到weight和bias是linear层的内置参数名,所以说这里就是指定的调用

接下来我们分别定义损失函数和优化算法即可

这里的loss类型就是平方差即L2范数

SDG这里指的是随机梯度下降算法

这里的学习率也就是我们在梯度优化公式中看到的步长
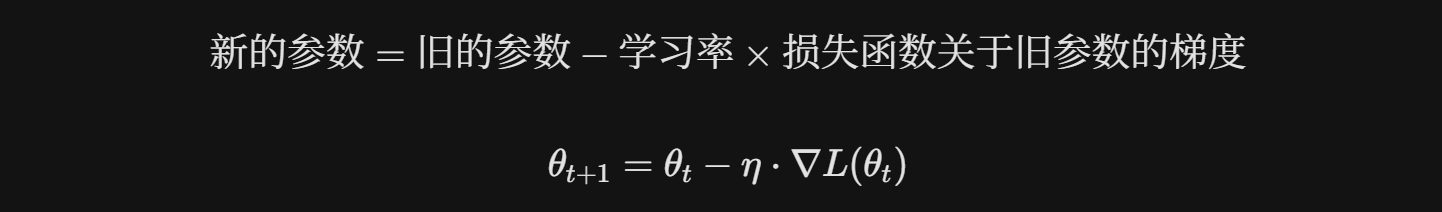

这里就是一个训练过程(总计三步)
其中.step()步整合了梯度的提取和参数的更新,也就是完成了优化的流程,不需要再手动赋值给参数(但是前面的backward计算梯度还是要写的,因为这个不在优化算法打包的范围内,同时记得梯度清零)
- Title: Notes on Section 3.3
- Author: bobown_yao
- Created at : 2025-12-03 00:00:00
- Updated at : 2026-01-17 16:18:07
- Link: https://bobownyao.github.io/2025/12/03/Notes-on-Section-3-3/
- License: All Rights Reserved © bobown_yao