Notes on Section 3.4
我们可以发现,一个回归模型可以用于预测量的问题,但是我们同样也想关注分类问题

所以其实是一个概率模型
对于一个分类问题,分类的类别往往是等价的(或者至少是没有量化可比性的,这时候我们需要引入新的标识系统来处理数据结构)
独热编码(one-hot encoding)就是这样一个例子
具体实现也很简单,对于N个元素的分类组,构建一个N维向量空间,则每个单独元素都是其中的一个基向量,且两两不同。这维持了范数的恒定,也保证线性无关

这里需要解释的是,首先输出层是由多个数据组成的,分别代表了机器在当先权重下对每个分类的预测的可能度,所以这些输出应是不相关的,其和也不符合概率的加和为100%的规律,而是只是由数值的大小来决定是这个类别的相对可能性
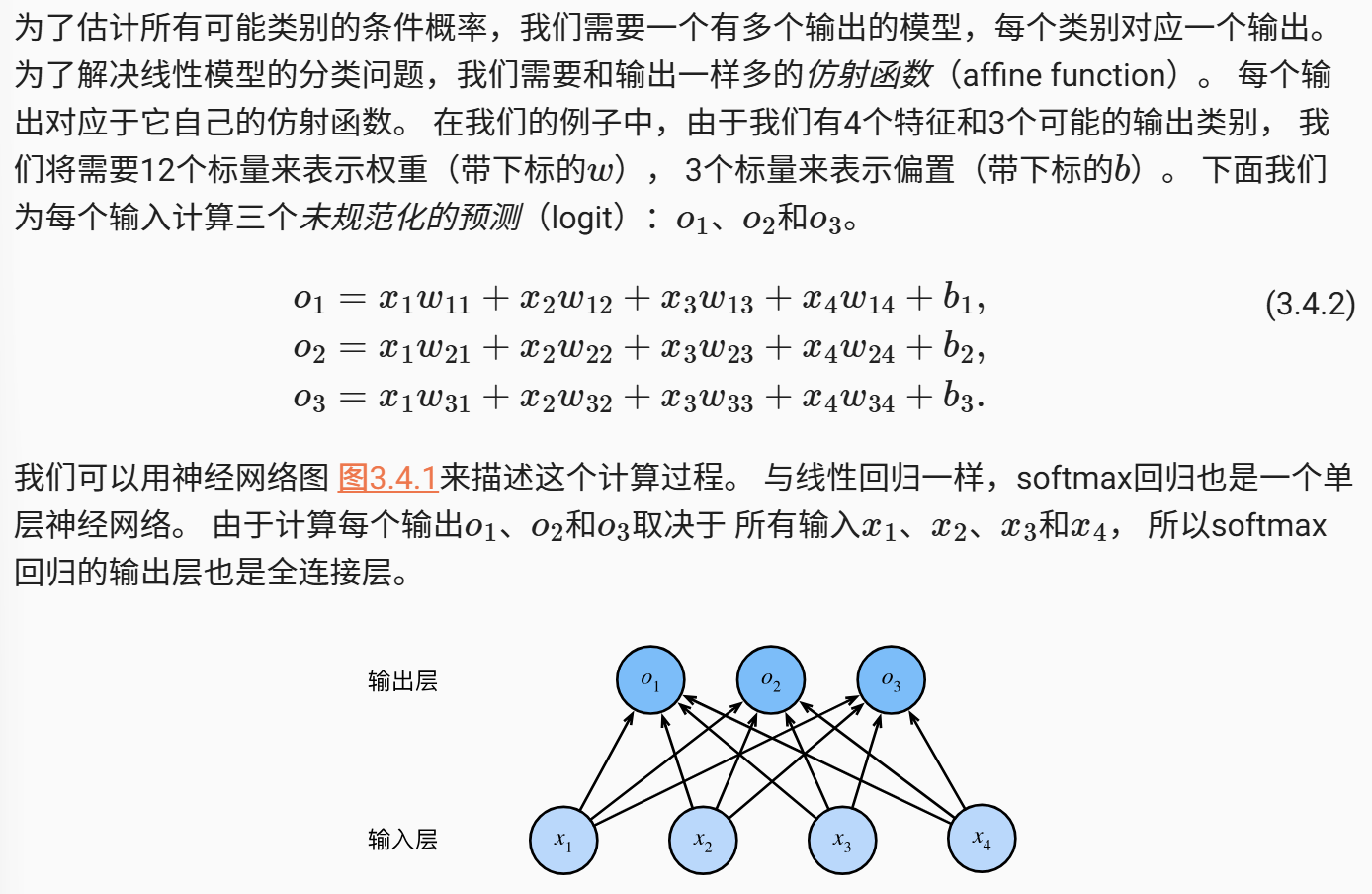
为了解决上述的一个非归一化的问题,我们引入softmax函数
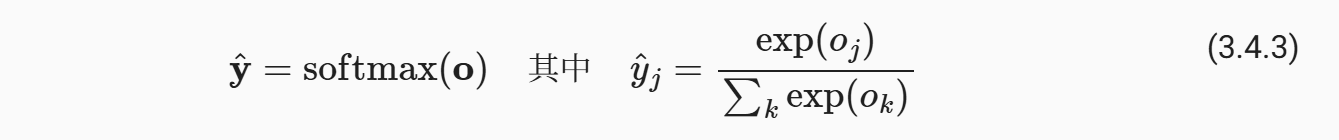
显然,上面的函数变换达到了要求,也没有改变各个输出之间的大小关系
然后我们可以取一定批量的样本然后矢量化,相当于是打包操作,这个操作主要是利用GPU多线程的特性来提高效率
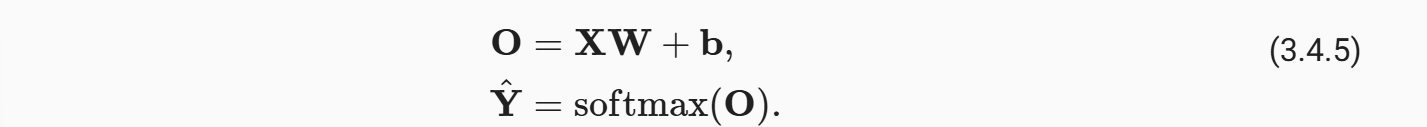
损失函数还是同理使用最大似然估计

这里的意思就是求这个模型准确预测这个批次中所有样本的概率,当然这个概率在样本数量大的时候会很小,所以我们接下来引入其负对数进行处理
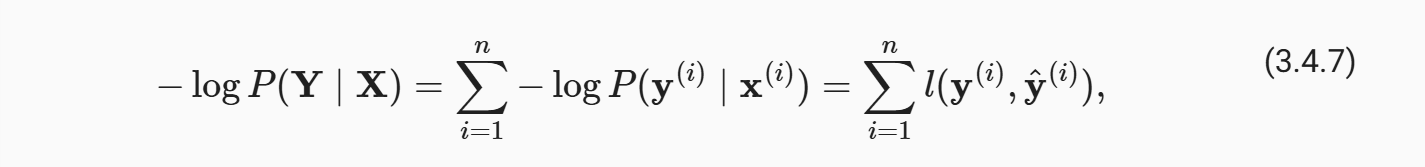
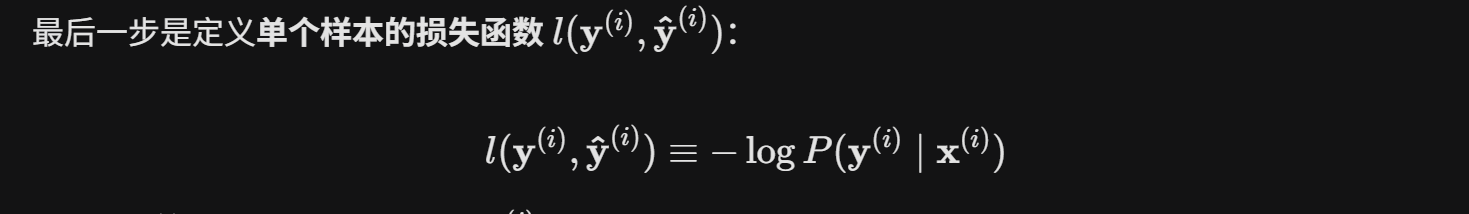
根据独热编码的特性,我们可以给出损失函数的等价变形,也称为
交叉熵损失(cross-entropy loss)
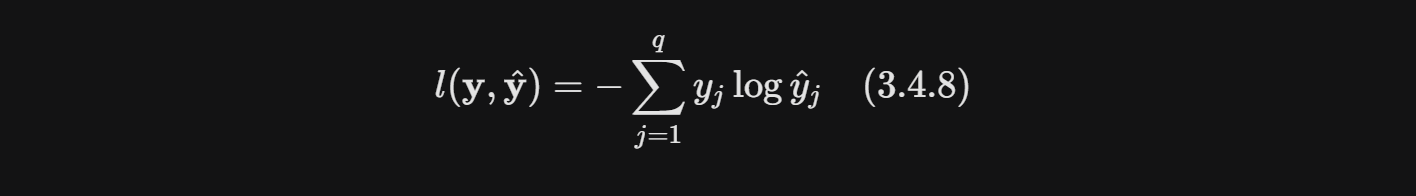
以下给出了等价推导

经过代数变换,我们可以得到以下简化公式(下标指的是分类标签)
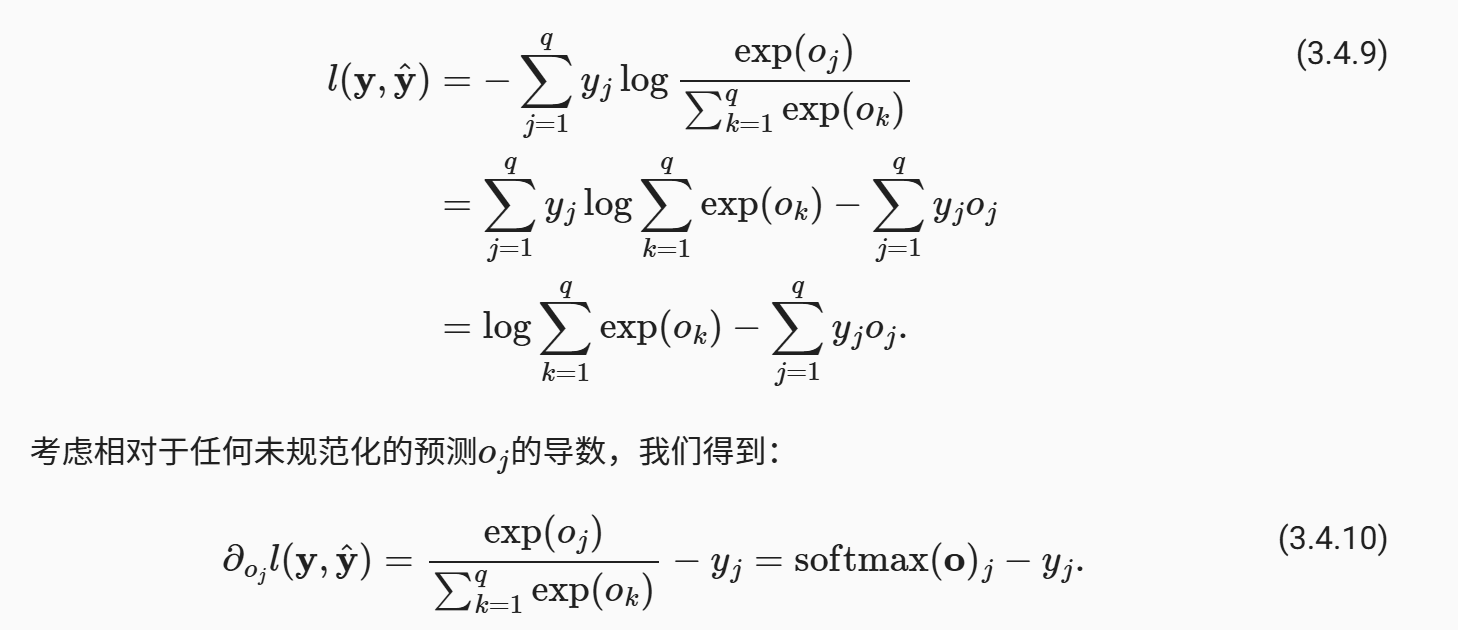
这个的导数相对是容易的
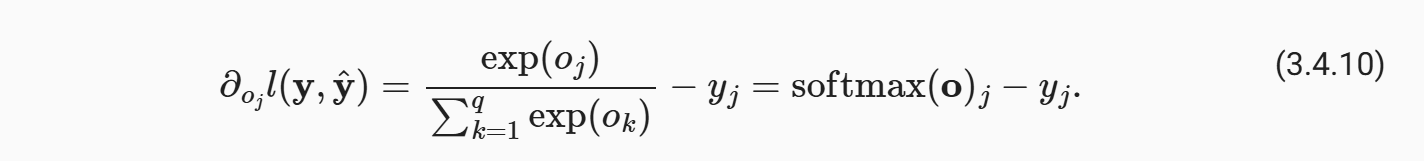
然后进一步回溯到W/b就可以得到需要的梯度了
然后我们关注一下信息熵部分的内容(香农熵)

我们这里涉及和交叉熵和香农熵本质联系

在训练单个样本的时候,香农熵是0(因为只有一个正确答案),所以说最小化交叉熵和交叉熵向香农熵趋近是等效的
- Title: Notes on Section 3.4
- Author: bobown_yao
- Created at : 2025-12-04 00:00:00
- Updated at : 2026-01-17 16:18:07
- Link: https://bobownyao.github.io/2025/12/04/Notes-on-Section-3-4/
- License: All Rights Reserved © bobown_yao