Notes on Section 4.8
这节研究的是初始化模型参数方面的考量
糟糕的初始化选择会导致一些问题,比如“梯度消失”和“梯度爆炸”

首先我们可以把每一层简化成一个变换,这个变换包括了常规的权重矩阵/偏置/非线性函数

这样我们就可以利用链式求导法则得到这个的表达式了

但是我们设想这样一种情况,也就是有多个线性层堆叠起来,这样的话我们的权重矩阵重叠起来,就很有可能被指数级放大或者缩小,以及ReLU等非线性函数的处理,也许会出现很小的值,这会导致梯度爆炸或者梯度消失

这里我们引入另外一个概念,也就是线性层的对称性这样一个性质
其主要阐述的就是,对于两个堆叠在一起的线性层,我们交换两个单元并且调整对应的权重结构,这样不会改变模型的效果,也就是,两个线性层本质是相同的(这从多个线性层本质上可以复合成一个线性层可以看出来)
事实上,训练模型的时候,多个线性层的表现往往差于单层,不仅因为其耗费了大量的内存,还有多层迭代的不稳定性和放缩特性(事实上非线性函数在同样权重的表现下也不会产生不同的梯度,由于其本质还是非随机的)
但是引入dropout则可以强行打破这个对称性,通过随机的丢弃一些神经元,这样的话每一层就会往不同的方向发展
Xavier初始化 可以配合以下链接
深度学习中的参数初始化方法:Xavier详细推导+pytorch实现 - 知乎

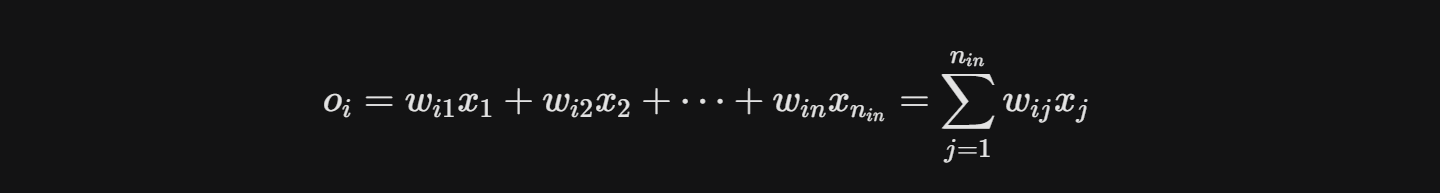
(配合这个食用就看的懂了)

因为每个输出对应的权重都是独立的,所以说向量协方差为0,可以拆开,这里我们得到了输出向量组元素的期望是0,然后方差也可以相同方式的展开
这个算法保证了输出向量组元素的方差等于输出向量的方差

- Title: Notes on Section 4.8
- Author: bobown_yao
- Created at : 2025-12-29 00:00:00
- Updated at : 2026-01-19 13:42:47
- Link: https://bobownyao.github.io/2025/12/29/Notes-on-Section-4-8/
- License: All Rights Reserved © bobown_yao