Notes on Section 4.9
训练模型的数据分布和应用环境的数据分布的不同很可能导致模型完全不同的表现。
同时,我们需要考量到模型本身对环境的影响,当模型在环境中进行决策时,环境可能会跟随决策而做出相应的变化,但是由于模型和环境是不交互的,所以这导致模型运行时的偏差甚至错误。
分布偏移(distribution shift)是我们此处需要考虑的问题,也就是训练时的数据和测试/实际应用时的数据结构和特征改变的这样一个可能
当然在偏移满足一定条件的时候,我们还是可以通过模型得到合理的答案
协变量偏移

条件分布P(y | X)保持不变
我们通俗的理解一下:我们处理问题的思路是(需求要素-逻辑链-结论),但是模型并不这样理解问题,事实上,模型并不会真正的理解哪些是真正的需求要素,而是相对单纯的对比相似性,这导致那些人类处理问题时往往会忽略的内容成为了模型在环境迁移时的阻碍(比如判断红绿灯时,天气的因素导致背景的色块完全不同,这可能影响模型的判断)
标签偏移
指的就是测试集中不同结果的分布和训练的数据不同
从独立性的角度看,模型其实不会产生非常大的偏差,但是如果我们在训练模型的时候也使用失衡的样本,那么模型处理在边界处的输出就不可避免地产生偏倚(比如将模糊的照片大部分分类为猫因为在训练集中有90%的样本是猫)
概念偏移
“这听起来很奇怪——一只猫就是一只猫,不是吗? 然而,其他类别会随着不同时间的用法而发生变化。”
变化的 不变的 example


基于这些可能的问题,我们提出分布偏移纠正/标签偏移纠正来解决这些问题
首先我们从上面可以看出两个偏差对应的变化和不变的关系
所以说我们可以分别在训练的时候增加对应的权重,这个权重的大小意味着当前参数在真实环境中的相对重要性/出现频率,所以我们也是正相关的放大其损失函数
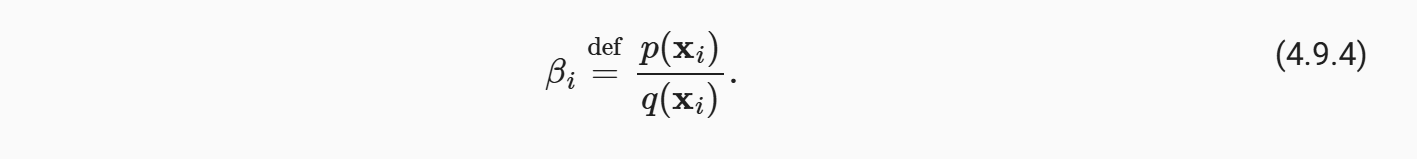
这里取对数计算本质是简化计算,只需要明白我们还是在估算权重beta的值
因为训练和测试的输入数据都是有的,所以说这个数值是可以计算的

同样的我们对于标签偏移也是这样解决,不过我们似乎没有办法获取目标分布
(这是一个问题!)
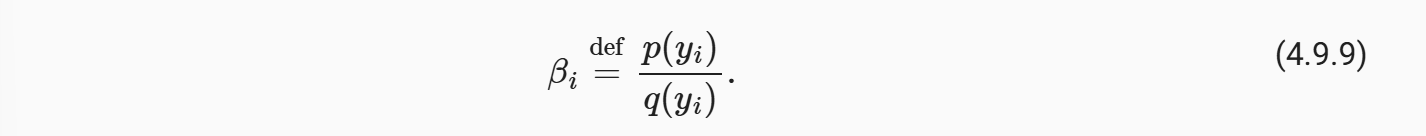
但是我们也有办法对这个值进行估算,首先我们可以用带有标签的训练集得到这个函数的混淆矩阵(也可以拿一个更加好的模型对拍)
混淆矩阵C是一个k*k矩阵, 其中每列对应于标签类别,每行对应于模型的预测类别。 每个单元格的值c_ij是验证集中,真实标签为j, 而我们的模型预测为i的样本数量所占的比例。
以及
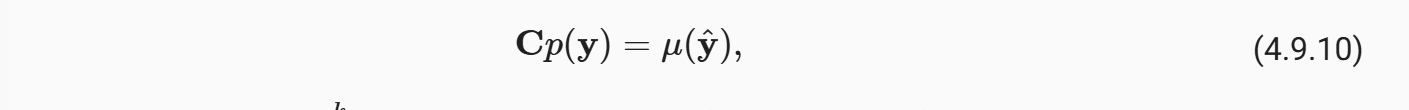
混淆参数*实际值得到的就是我们模型的预测输出值,这样的话通过矩阵的逆运算我们就可以得到p(y),也就得到了我们需要的权重beta
对于概念偏移纠正,这个不属于数据上的问题,所以很难用原则性的方式解决
本章节的剩余部分介绍了不同的训练方式
批量学习
在线学习(交互式迭代)
控制
强化学习
- Title: Notes on Section 4.9
- Author: bobown_yao
- Created at : 2025-12-30 00:00:00
- Updated at : 2026-01-19 13:42:54
- Link: https://bobownyao.github.io/2025/12/30/Notes-on-Section-4-9/
- License: All Rights Reserved © bobown_yao