Notes on Section 7.5
深层神经网络的训练是相对复杂的,因为我们很难在较短的时间内达到收敛。
这里我们可以先思考一个问题:对于一个多层的神经网络模型,往往是下层在总结更加具体的特征,而上层提取的则是相对抽象的特征。但是根据反向传播的优化器则是从下往上更新参数,意味着每个参数都是在上层固定的先验下向优化方向收敛,这导致上层在还未有序提取特征的时候,下层的参数优化变得没有意义。
另外一个是关于学习率的调整,我们可以设想有些层的参数的变化范围是远大于别的层的(相对于初始化位置),这时候需要动态的调整lr来解决这个
最后一个是关于正则化考量,因为复杂的模型倾向于过拟合。
对于上面这个问题,我们将引入一些技术来解决,其中之一是批量规范化(BN,batch normalization)
“批量规范化应用于单个可选层(也可以应用到所有层),其原理如下:在每次训练迭代中,我们首先规范化输入,即通过减去其均值并除以其标准差,其中两者均基于当前小批量处理。 接下来,我们应用比例系数和比例偏移”

我们可以按照以下顺序理解
 这一部分解决上面陈述到的一个问题,也就是lr适用的问题,在归一化的处理下,我们可以用同样的lr适配不同深度的层,而不用担心浅层不收敛的一系列可能问题。
这一部分解决上面陈述到的一个问题,也就是lr适用的问题,在归一化的处理下,我们可以用同样的lr适配不同深度的层,而不用担心浅层不收敛的一系列可能问题。
这里我们需要知道——BN在反向传播中的效果于前向传播是高度对称的

第二部分

使用代码实现一个BatchNorm(可以同时处理Dense/Conv)
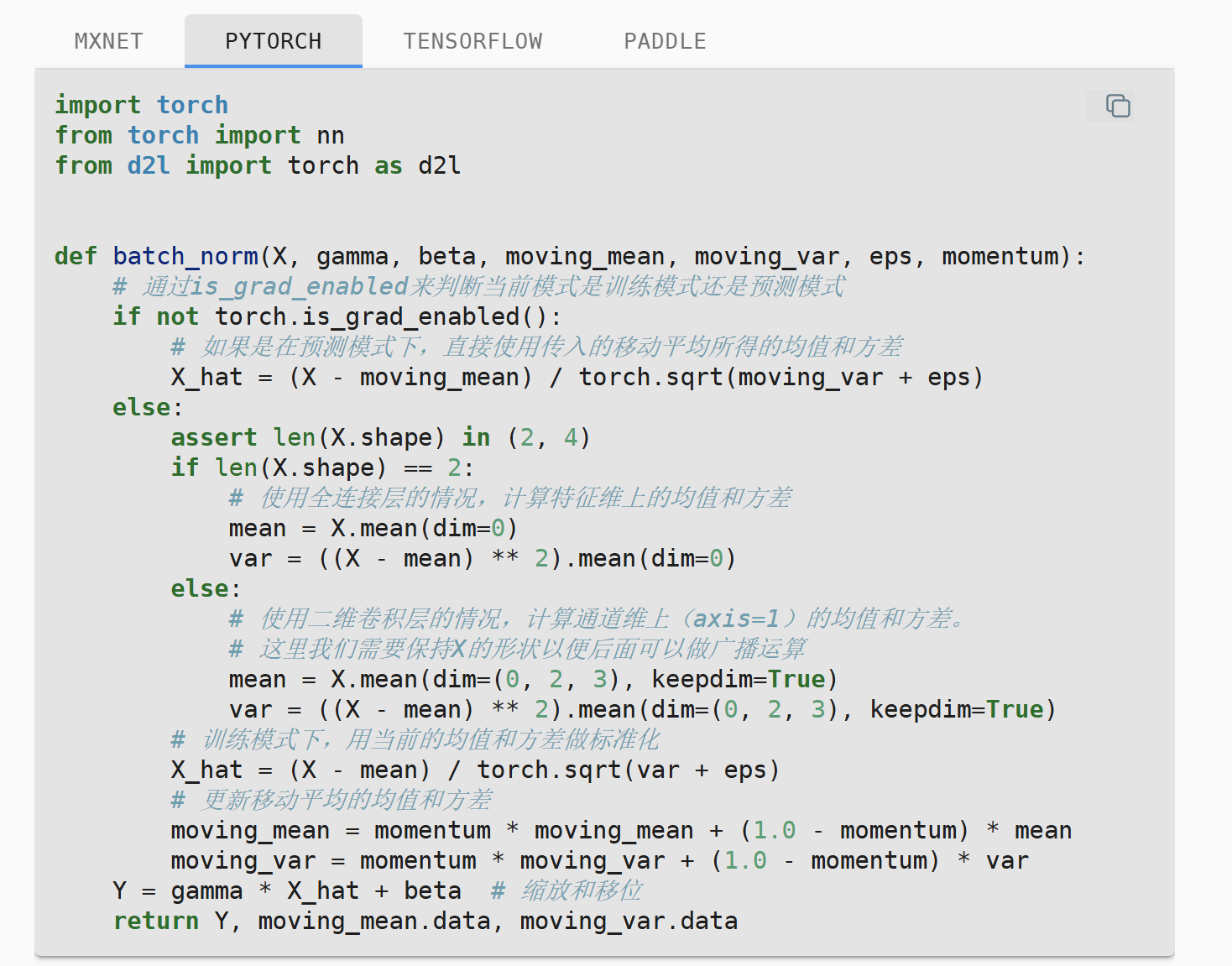
最后,必须说明的是,和dropout一样,BN在训练模式和预测模式中的表现形式也有差异,在训练模式中,BN会提取小批次的样本的均值+标准差信息。而在预测模式中,这个数值会被替换成全局近似值(这通过在训练时迭代记录信息实现),不再更新。当我们使用这个模型的时候,其中的BN其实就和Dense相同。
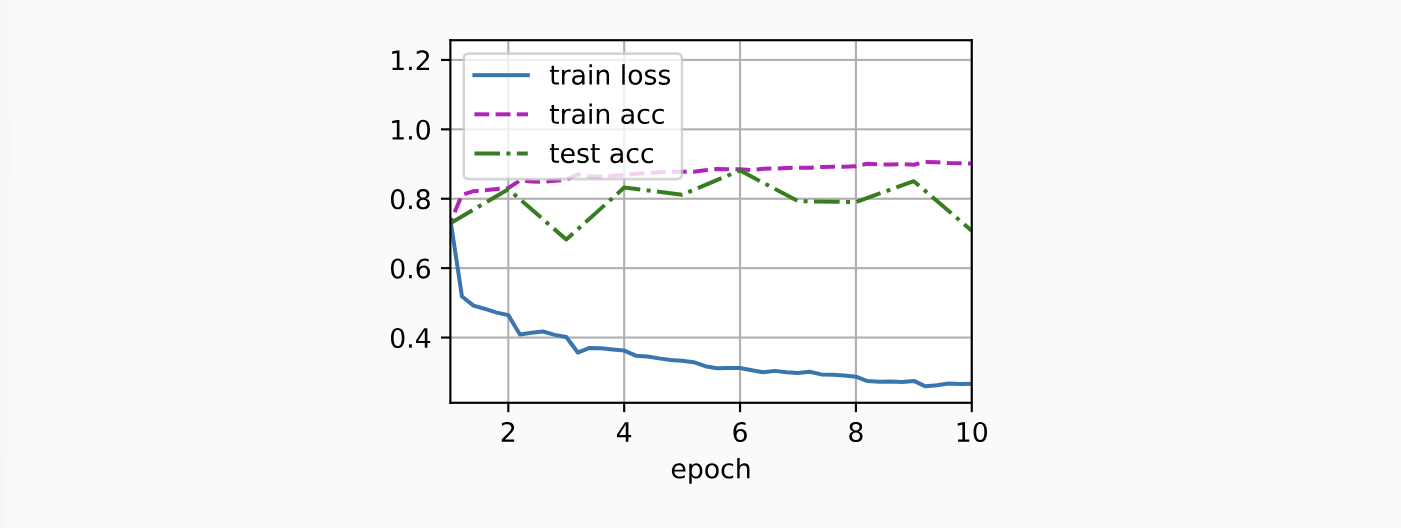
这里面的一个事实是,我们发现trainloss的小幅度震荡变大了,这其实和底层参数的相对较大幅度的改变有关
- Title: Notes on Section 7.5
- Author: bobown_yao
- Created at : 2026-01-20 00:00:00
- Updated at : 2026-03-08 19:46:44
- Link: https://bobownyao.github.io/2026/01/20/Notes-on-Section-7-5/
- License: All Rights Reserved © bobown_yao