Notes on Section 7.4
通过之前对于CNN框架的理解,我们发现了多层卷积层可以扩大感受野,进而提取更多特征。然后可以使用1*1的卷积层强化特征,放大通道数来直接实现分类。
现在我们可以设想一下,在图像处理中,特征的大小和出现频率可能不完全是一样的。所以说使用不同大小的卷积核并行处理同一张图片是否可以得到更好的效果?
以下是GoogleNet的Inception块的结构
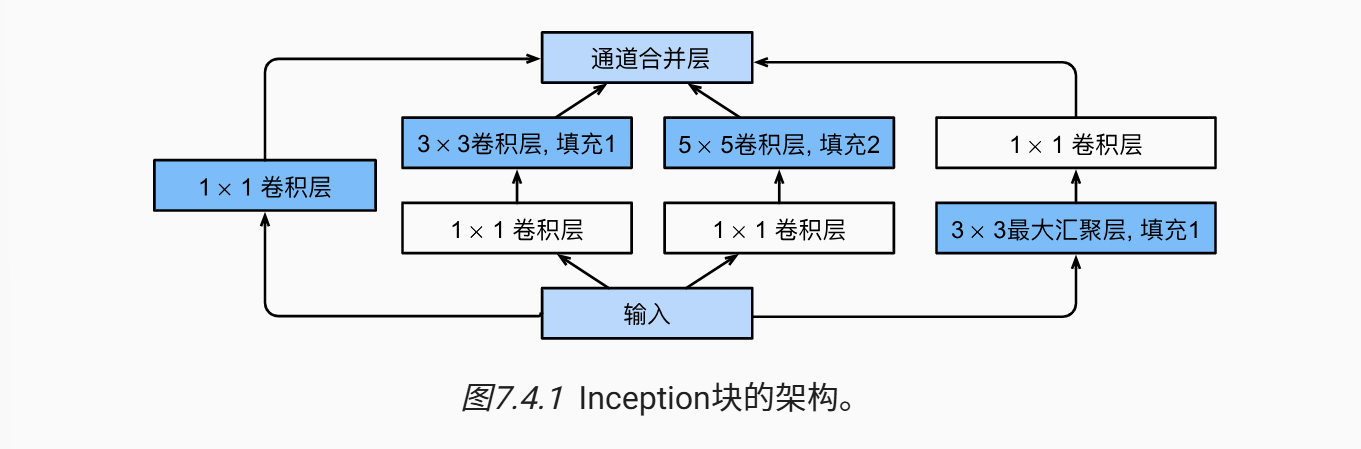
“Inception块由四条并行路径组成。 前三条路径使用窗口大小为1*1、3*3和5*5的卷积层,从不同空间大小中提取信息。 中间的两条路径在输入上执行1*1卷积,以减少通道数,从而降低模型的复杂性。 第四条路径使用3*3最大汇聚层,然后使用1*1卷积层来改变通道数。 ”
我们可以发现在执行3*3或是5*5卷积的时候,先执行的是1*1卷积,这一层主要是减少了通道数,防止参数爆炸

然后我们来考虑一下为什么要这样分支处理,这基于“赫布理论(Hebbian principle)”和“稀疏矩阵分解”。前者可以被引申为:如果某些特征(神经元)在观察大量数据时经常同时出现(高度相关),那么它们就应该被组织在一起处理。后者则考虑到,在计算稀疏矩阵的时候,计算机的效率相对低,而处理密集矩阵的时候则很快,所以可以用密集子矩阵来近似稀疏矩阵。
看一下Inception块的架构,这段代码模拟了网络的构造(从__init__看出)和计算逻辑(从forward部分可以看出)其中c1-4分别代表了对应分支最终的输出通道数(c2,3为列表格式)
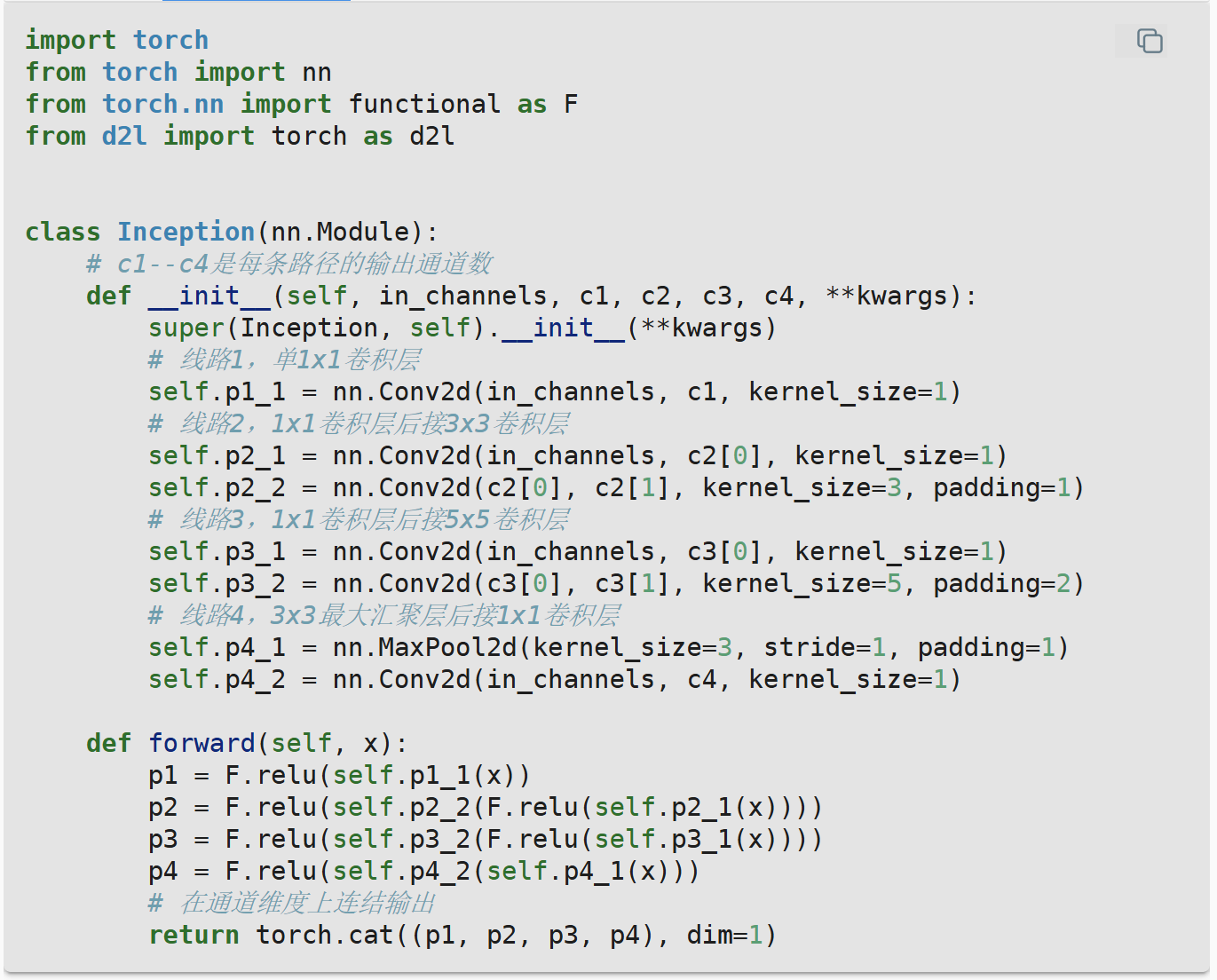
以下是Inception块的全貌(这里最后还有一个Dense,但是是非常轻量级的,全连接层可以更好的解释一些不太逻辑的元素,同时方便网络的迁移,比如说分类数从1000到100,只需要改变Dense参数)
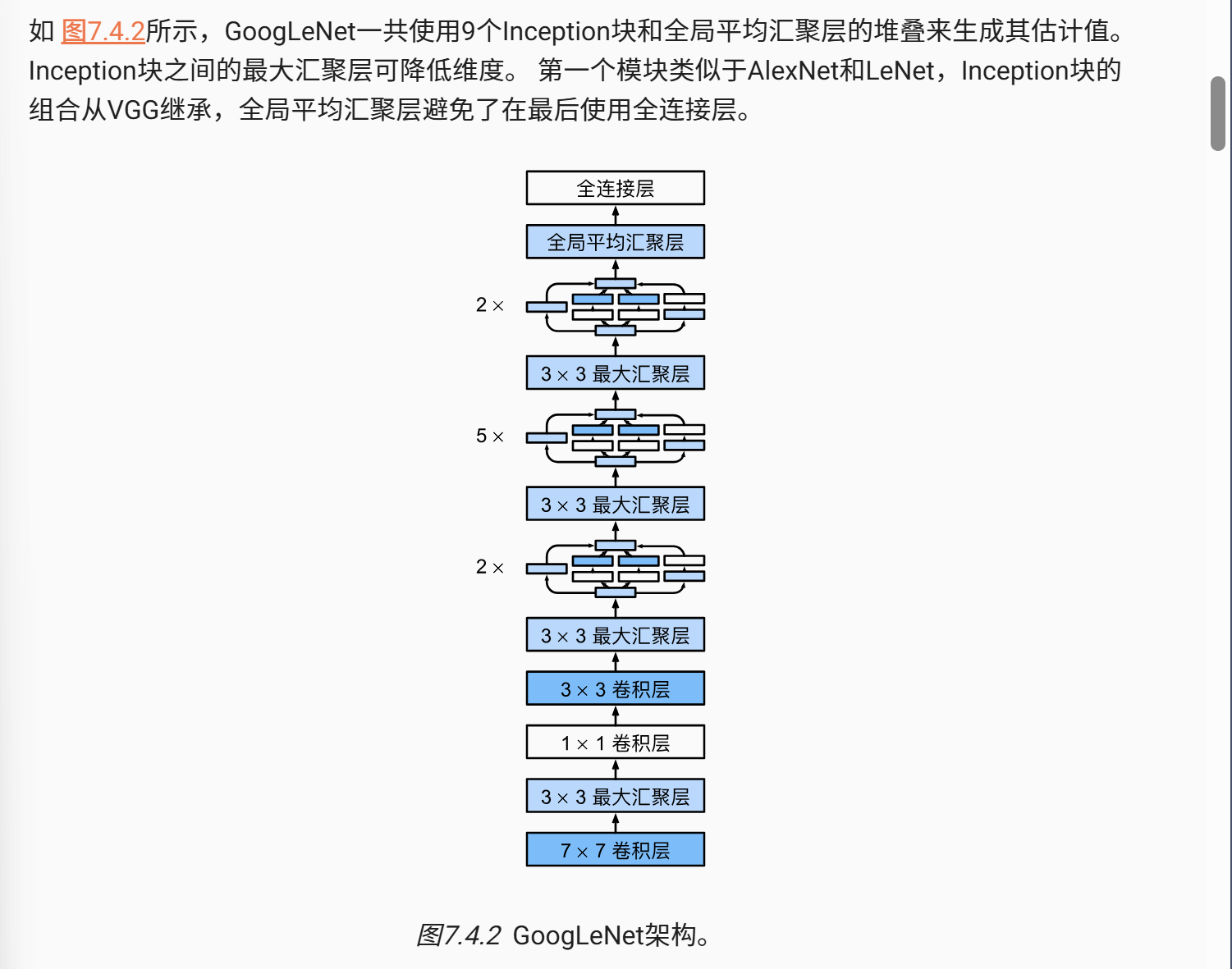
GoogLeNet同时借鉴了NiN的汇聚层代替全连接,还有VGG的小卷积核优势,在参数方面有很大的优化
以下比较了VGG块和Inception块的参数开销(不过这里VGG应该用的是两个3*3,不过即使也只少了一半参数)

不过GoogleNet的结构相对固定,其中的超参数需要人工调节,这也导致了其非常复杂的网络超参数设置。不过网络深度的代价是大量优化·的参数开销。
- Title: Notes on Section 7.4
- Author: bobown_yao
- Created at : 2026-01-20 00:00:00
- Updated at : 2026-03-08 19:46:44
- Link: https://bobownyao.github.io/2026/01/20/Notes-on-Section-7-4/
- License: All Rights Reserved © bobown_yao