Notes on Section 7.3
在早期CNN网络中,我们始终遵循着“先卷积,后稠密”的网络构造,这主要是为了尽可能的提取表征的空间结构并弱化空间位置带来的影响。
为了进一步强化表征,网络中的网络(NiN)提供了一个非常简单的解决方案:在每个像素的通道上分别使用多层感知机
“NiN的想法是在每个像素位置(针对每个高度和宽度)应用一个全连接层。 如果我们将权重连接到每个空间位置,我们可以将其视为1*1卷积层,或作为在每个像素位置上独立作用的全连接层。”
我们可以这样理解1*1卷积层对于特征的增强作用:首先我们认为经过卷积处理之后,每个像素位置都一定程度的携带了特征标签,然后我们通过1*1卷积层处理通道值,这一步增强了特征信息(主要体现为通道之间的特征组合),然后再使用ReLU激活(这一步主要是为了筛除杂乱信号,便于提取高级特征)
然后我们还观察到一个NiN内部含有两个1*1Conv+ReLU单元,这是因为NiN的主旨就是Network in Network,所以我们在块内部模拟了一个小的MLPConv,如果只有一层Conv,那么本质就是一个卷积+激活,没有多层感知的效果
下图展示了NiN的基本结构
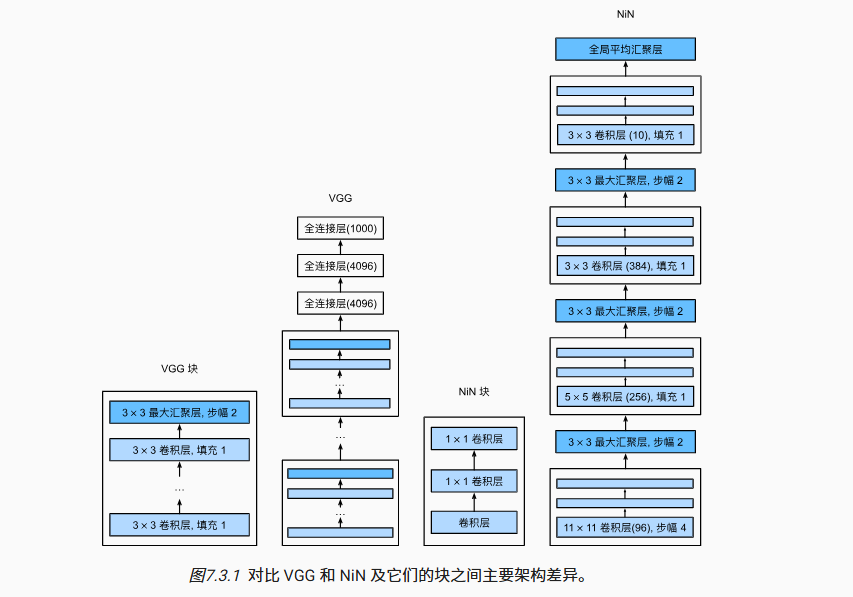
我们会观察到原始的NiN中使用了11*11卷积核,我们可以用如下的时间表解释
AlexNet(2012)-NiN(2013)-VGG(2014)
这说明其实NiN可以用更小的多个卷积核进一步优化性能
NiN和AlexNet之间的一个显著区别是NiN完全取消了全连接层,NiN使用一个NiN块,其输出通道数等于标签类别的数量。最后放一个全局平均汇聚层(global average pooling layer),生成一个对数几率 (logits)。
我们可以这样理解,最后一层的通道数量就是我的分类类目数量,于是直接取每个通道的GAP,然后用softmax输出最后的结果
这里我们可以总结一下NiN相比传统的CNN卷积+稠密的优势所在
1. 首先是参数的减少,NiN直接取消了全连接层,削减了大量参数
2. 其次是最后GAP作为分类器的输入,泛化效果相比Dense更好
3. 另外因为取消了全连接层,NiN对不同分辨率的图像的接受程度更好,提高了网路的灵活性
4. 通过强化特征图通道与类别的对应关系,提高了特征的解释性和空间相关性
不过NiN的局限性在于收敛速度较慢以及对特征提取器(1*1卷积层)的高度依赖
我们可以设想两个问题:
1. 为什么NiN的参数减少显著?
2. 为什么最后使用全局平均池化GAP而不是全局最大池化GMP?
一下给出了一些参考


- Title: Notes on Section 7.3
- Author: bobown_yao
- Created at : 2026-01-18 00:00:00
- Updated at : 2026-03-08 19:46:44
- Link: https://bobownyao.github.io/2026/01/18/Notes-on-Section-7-3/
- License: All Rights Reserved © bobown_yao