Notes on Section 7.1
我们先来看经典机器学习的流程


但是这些算法都基于预设的特征,这导致了其局限性。进一步的,我们希望机器可以自己学习特征
不过这里我们可以先引入一下硬件更迭对于接下来介绍的一些算法出现的影响
“GPU可优化高吞吐量的4*4矩阵和向量乘法,从而服务于基本的图形任务。幸运的是,这些数学运算与卷积层的计算惊人地相似。”
“那么GPU比CPU强在哪里呢?”
“首先,我们深度理解一下中央处理器(Central Processing Unit,CPU)的核心。 CPU的每个核心都拥有高时钟频率的运行能力,和高达数MB的三级缓存(L3Cache)。 它们非常适合执行各种指令,具有分支预测器、深层流水线和其他使CPU能够运行各种程序的功能。 然而,这种明显的优势也是它的致命弱点:通用核心的制造成本非常高。 它们需要大量的芯片面积、复杂的支持结构(内存接口、内核之间的缓存逻辑、高速互连等等),而且它们在任何单个任务上的性能都相对较差。 现代笔记本电脑最多有4核,即使是高端服务器也很少超过64核,因为它们的性价比不高。”
“相比于CPU,GPU由100-1000个小的处理单元组成(NVIDIA、ATI、ARM和其他芯片供应商之间的细节稍有不同),通常被分成更大的组(NVIDIA称之为warps)。 虽然每个GPU核心都相对较弱,有时甚至以低于1GHz的时钟频率运行,但庞大的核心数量使GPU比CPU快几个数量级”
我们可以比较LeNet和AlexNet的架构
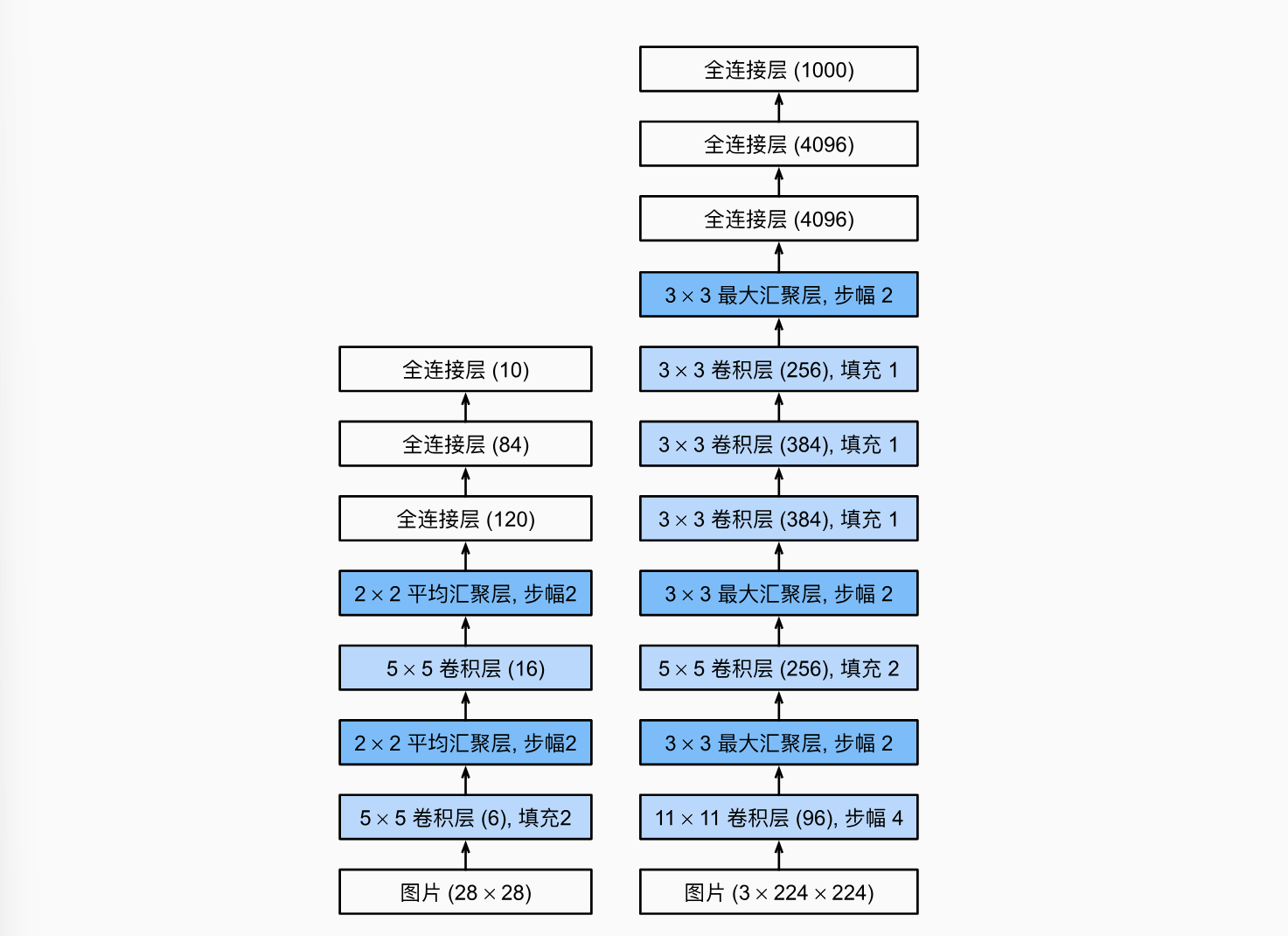
可以说AlexNet是放大增强版,而且更多的卷积层来放大感受野对于分辨率更高的图像也是必要的举措
(实现代码略)
这里我们不禁思考一个问题,也就是AlexNet的泛化性能。因为AlexNet是针对ImageNet的100w张224*224的共1000类的照片作为数据参照设计的。
- 比如说用10*10或者10000*10000的图片作为AlexNet的训练集,那么效果是否下降
- 我们假设224*224还有100*100还有500*500分别作为训练集(测试集也是对应的分辨率),那是不是还是224*224的训练效果最好?也即,AlexNet是不是对于224*224图片分辨率设计的特化模型,而当分辨率偏移的时候训练的效果就会下降(即使不是下降很快)
- AlexNet的参数是对于分类数量已知的先验的情况下优化的吗,比如说训练集有10万的类目,或者只有10个类目,这个神经网络的质量是否会下降呢
对于以上三个问题,答案都是True,这也展现了AlexNet作为早期CNN的局限性
- Title: Notes on Section 7.1
- Author: bobown_yao
- Created at : 2026-01-17 00:00:00
- Updated at : 2026-01-21 11:36:28
- Link: https://bobownyao.github.io/2026/01/17/Notes-on-Section-7-1/
- License: All Rights Reserved © bobown_yao