Notes on Section 8.3
基于条件概率关系我们可以如下定义文本序列的预测
“为了训练语言模型,我们需要计算单词的概率, 以及给定前面几个单词后出现某个单词的条件概率。 这些概率本质上就是语言模型的参数。”

基于计数(Count-based)的 n-gram 语言模型。是比较基础的一种序列模型。对于单个语素我们可以求其在文本中出现作为开头的次数,除以总的句子数量,这样估计以某个单词开头的

拉普拉斯平滑(Laplace Smoothing) - 知乎
拉普拉斯平滑是一种思路,以下是其的一个变形。具体操作为,用一个可调的超参数代替+1操作,然后,对于多元(>1)的部分,我们使用当前值的频率概率作为补偿(也就是说,就算ab组合没有出现过,也根据b的出现频率,适当的考虑这个组合的生成)

不过这也是一个相当简单的处理,对于复杂文本的处理效果肯定是不佳的

以下我们用代码来观察文本数据中的一些统计量
在这里,corpus = [token for line in tokens for token in line]相当于是两个嵌套的循环,最终从内层循环中取出元素(也就是每一个单词,组成列表)
我们打印8.2中文本的前10个高频词

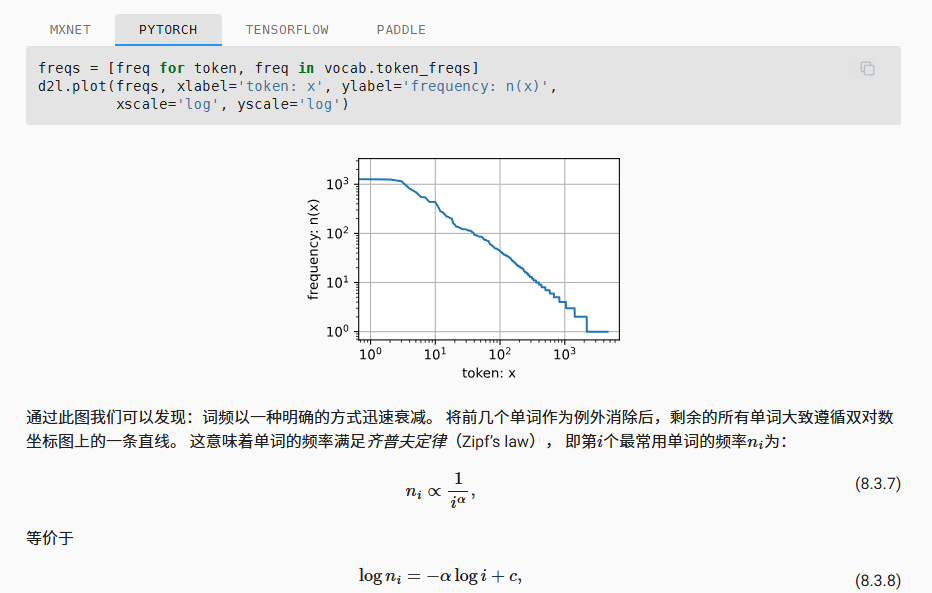
“正如我们所看到的,最流行的词看起来很无聊, 这些词通常被称为停用词(stop words),因此可以被过滤掉。 尽管如此,它们本身仍然是有意义的,我们仍然会在模型中使用它们。 此外,还有个明显的问题是词频衰减的速度相当地快。”
我们刻画词频下降和次序的关系,这里的Zipf’s law本身是一个经验公式,但是其真实的反映了大部分文本单词的分布情况——“齐普夫本人提出,语言演化遵循“最省力原则”。说话者希望词汇量越小越好(省事),而听话者希望词汇越精确越好。这种博弈导致了高频词极简且通用,低频词精准但罕见的分布。”
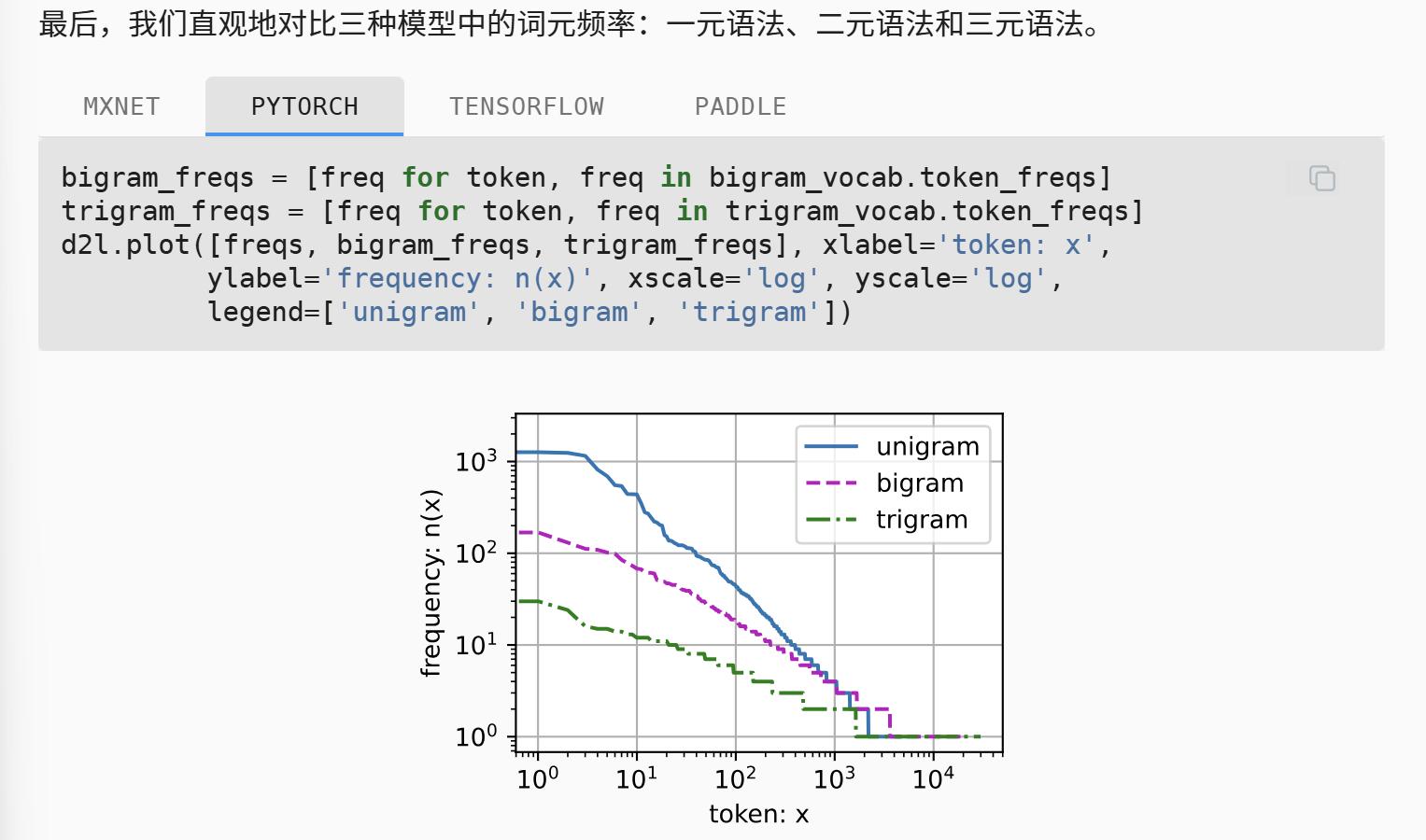
我们还可以观察词组(也即二元语法和三元语法)
这里在处理内容的时候,我们有两个选取数据的参数:batch size/time step(时间步)
“在自然语言处理中,一个时间步对应一个语素(Token),这个语素可以是一个字符,也可以是一个单词。 如果 $n=5$,你的训练序列里就有 5 个语素。”
以下我们先了解随机采样的实施方法
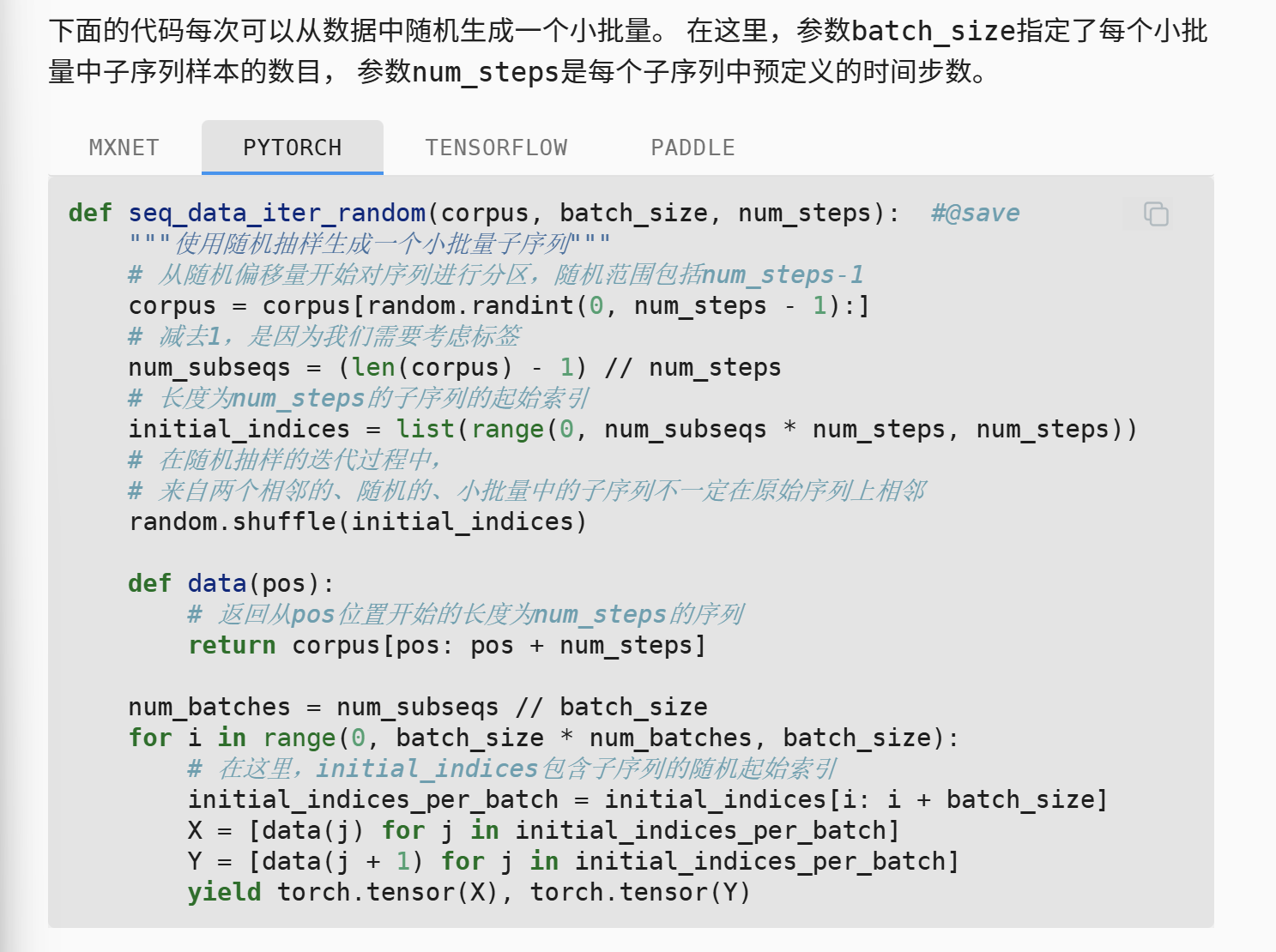
操作流程是,我们先随机的切掉开头的一点元素(偏移量),然后按时间步计算总的元素数量,最后取出所有的开头索引,并打乱。
注意我们最后这里用yield每次取出一组训练集
另外一个方法是使用顺序分区
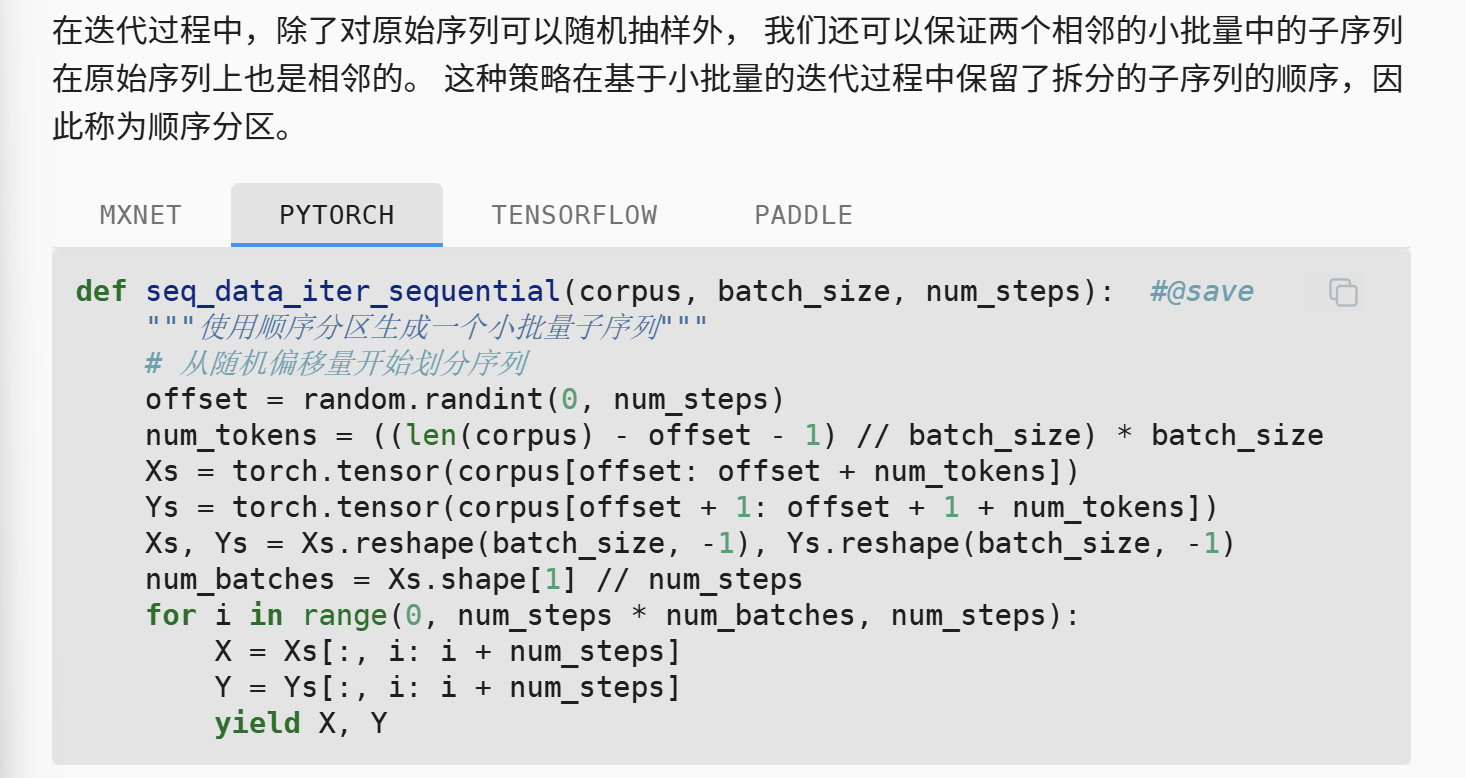
顺序分区的思路是,对于一个长文本,在偏移量处理之后,整除的分成B份,然后训练的时候就从每一份的头向尾遍历,且是所有B份并行。
循序分区的一个好处就是可以保留隐藏状态,这个有效增加了模型的时间记忆

- Title: Notes on Section 8.3
- Author: bobown_yao
- Created at : 2026-02-11 00:00:00
- Updated at : 2026-03-08 19:46:44
- Link: https://bobownyao.github.io/2026/02/11/Notes-on-Section-8-3/
- License: All Rights Reserved © bobown_yao