Notes on Section 8.5
这一部分是RNN的构建
在8.4中我们明确了数字编码向独热编码的映射
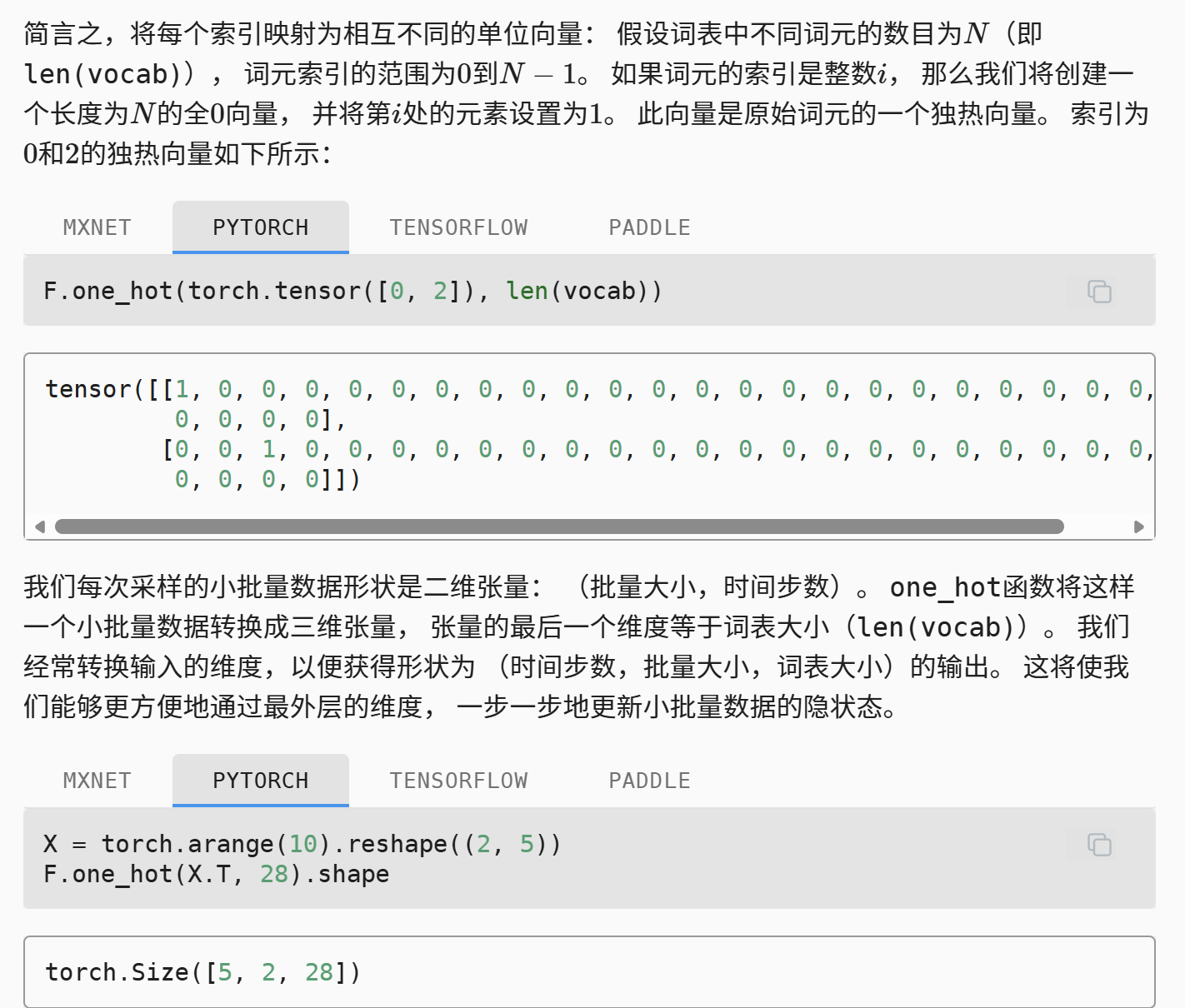
最后一个代码块展现了如何从数字索引向独热编码映射,通过one_hot函数。在这里,X是一个2*5矩阵,也就是2个分段,每个分段5个token(这个分法说明我们将使用顺序分区)。然后,通过transpose+独热编码(这里假设词典长度是28).
从输出的结构我们可以理解每个批次的输入数据
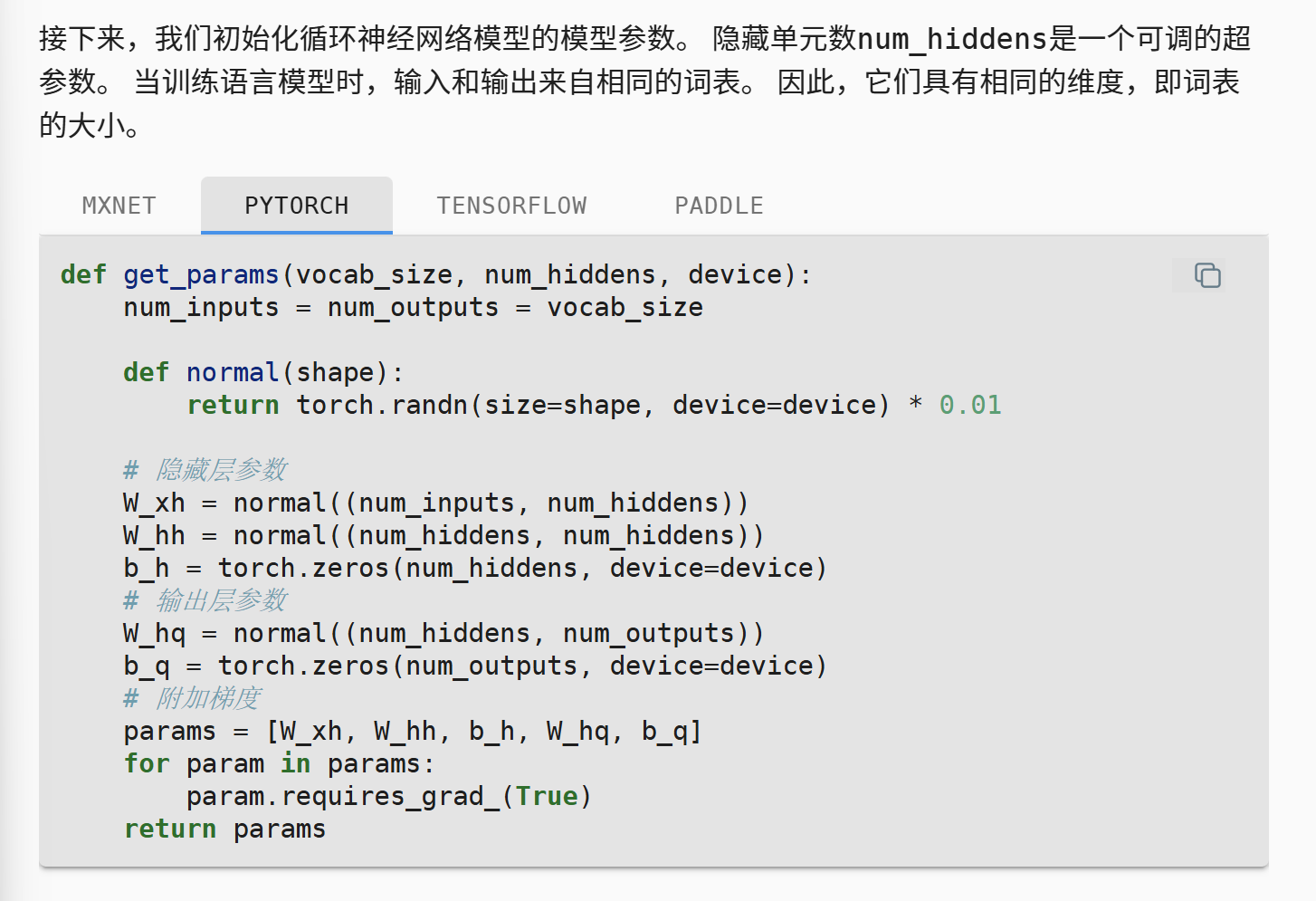
隐藏状态是一个扁平向量,也就是H,这个向量的长度是一个可以调控的超参数
然后我们需要初始化隐藏状态,一开始是0(因为第一个位置没有前序记忆)。
每个batch有一个自己的隐藏态(因为是一条线),所以说这个记录隐藏状态的容器是batch_size*num_hidden

这里提到的“使用元组可以更容易地处理”是因为我们需要考虑其他的RNN架构,元组的不可变性和顺序性便利了状态的传递


接下来需要解决的一个问题是关于梯度的,对于长度为T的序列,T较大的时候,可能导致梯度爆炸或者梯度消失。所以需要额外的梯度支持,比如梯度裁剪

根据Lipschitz continuous,我们可以根据常数L来圈定这个函数的陡峭程度(也就是输出导致输出波动最大的点)。不过,从另一个角度来看,L是不可知的,我们无法分析模型参数对应的函数,不过我们可以从一个试验性的训练中摘取梯度的范数,从而观察梯度的变化和极值。
然后我们就可以进一步确定lr

另外我们可以手动的调整梯度的长度(这个和间接调整lr的切入方式不一样),但这个只能解决梯度爆炸的问题,对于梯度消失则无能为力

然后可以开始搭建训练框架

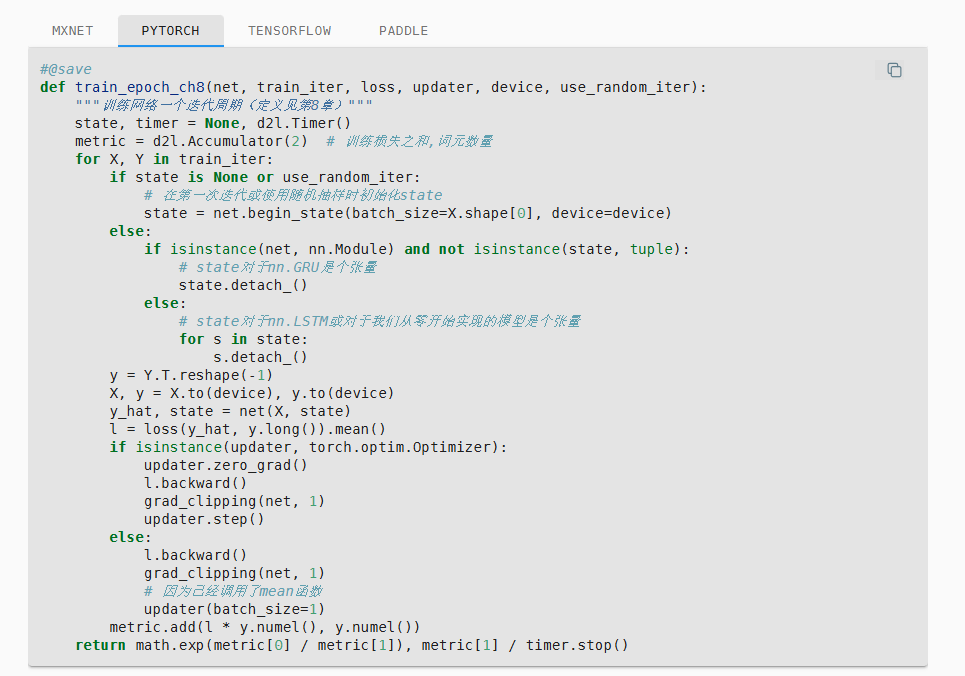
其中提到了分离梯度的策略,主要是通过如下部分实现的
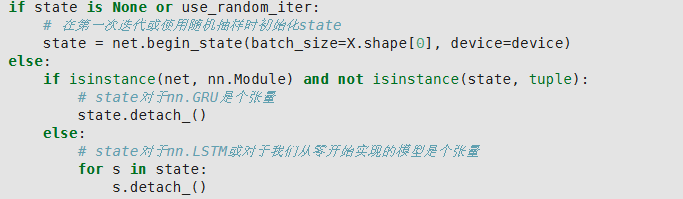
这部分的效果是:
state是所有的并行批次的隐藏状态的一个元组,s是对应里面的单个H,将其每个分别分离梯度

观察一下效果(这里应该是使用了字符作为训练粒度)
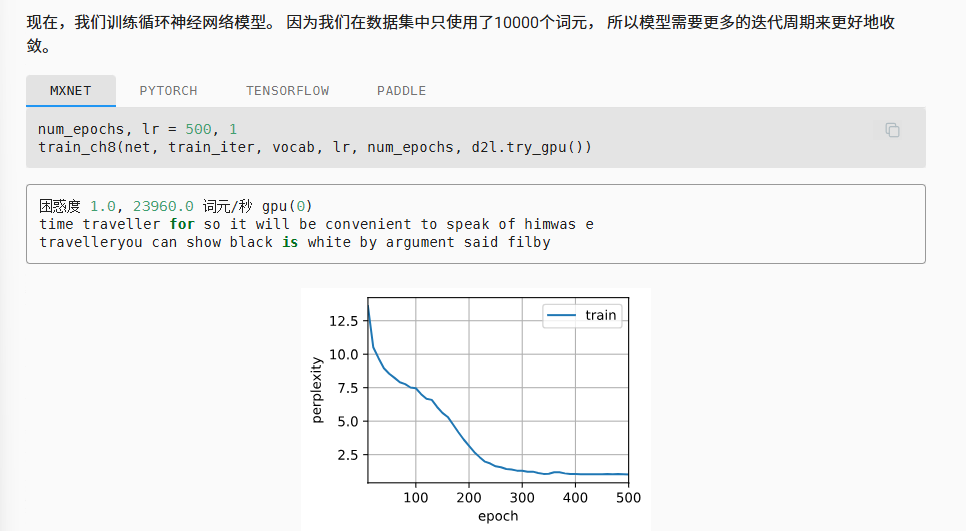
这里我们发现perplexity趋于1,但是模型给出的语句依然存在拼写/结构问题,首先是因为训练样本数量太少,其次和字符为粒度的切分方法有关。
- Title: Notes on Section 8.5
- Author: bobown_yao
- Created at : 2026-02-21 00:00:00
- Updated at : 2026-03-08 19:46:44
- Link: https://bobownyao.github.io/2026/02/21/Notes-on-Section-8-5/
- License: All Rights Reserved © bobown_yao