Notes on Section 8.7
本节主要是进一步介绍了上面用到的关于分离梯度/梯度裁剪的一些数学方面的解释
RNN中的backwards结构略有差异,总的来说,属于通过时间反向传播(backpropagation through time,BPTT)。对于一个长度为T的序列,我们有损失函数为每一步的损失函数之和(或者除以序列长度以标准化),对于这个序列,当我们尝试计算从t到1步的梯度的时候,梯度爆炸和消失的问题就出现了,同时,这个在计算时间和内存上也是无法实现的。
我们先结合RNN的架构回顾梯度算法的推导



简化来说,我们可以这样表示反向传播的梯度计算(其中o其实就是函数g(h,w))

这个展开中,最难处理的是第三步,也就是h对于w的偏导

这里最后一个公式中,左边第一项是全偏导,考虑了w影响h的所有路径,然后右边第一项是显式偏导(也就是把h_(t-1)视为常数),第二项是考虑了h下一级路径的偏导(事实上这个会一直延伸到第一项,也是因此这个计算图会非常的长)
这个关系也可以用如下数列表示
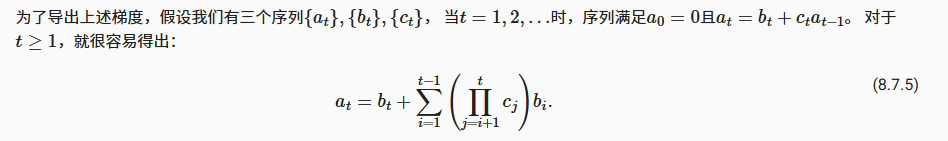
事实上,有两种分离梯度的策略,分别是固定步长截断和随机截断。
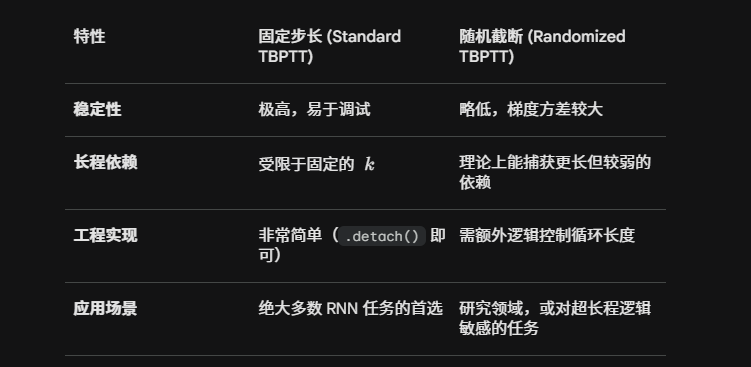
固定步长截断就是递归到确定的位置然后直接把余项设为0。
随机截断会复杂一点,数学上讲,其较为自洽的模拟了全导数的计算。具体实施的方案是,每一次递归的时候都有一定的概率截断,或者是继续延申,因为长序列的概率比短序列相对小,所以我们对于这一部分补偿对应概率倒数的系数。最终,期望上,模拟了全导数。

需要注意到的是,对于这两个切分策略,其对象都是序列,这意味着一些梯度对应的计算图会很短
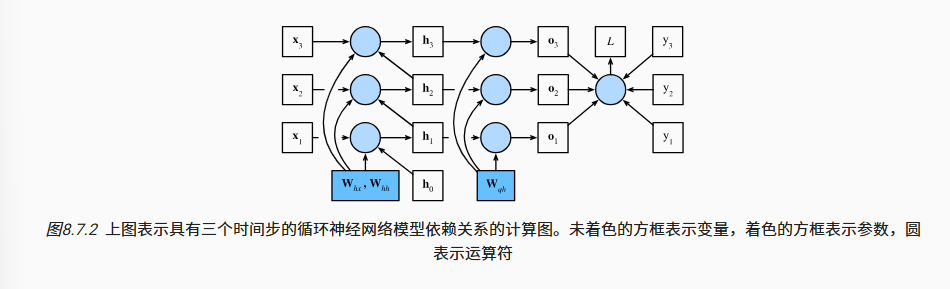


配合以下食用



这个部分具有数列的特征,所以说最后会得到8.7.15,我们可以从幂次项中看到,这个部分很容易发散或者消失,这也是我们需要截断的原因
- Title: Notes on Section 8.7
- Author: bobown_yao
- Created at : 2026-02-22 00:00:00
- Updated at : 2026-03-08 19:46:44
- Link: https://bobownyao.github.io/2026/02/22/Notes-on-Section-8-7/
- License: All Rights Reserved © bobown_yao