Notes on Section 9.4
这部分的讨论先从动态规划之于马尔科夫链的的递归计算简化开始
首先RNN架构是基于以下的隐马尔科夫链假设的,也就是h变量之间只在相邻位置链接发生关系
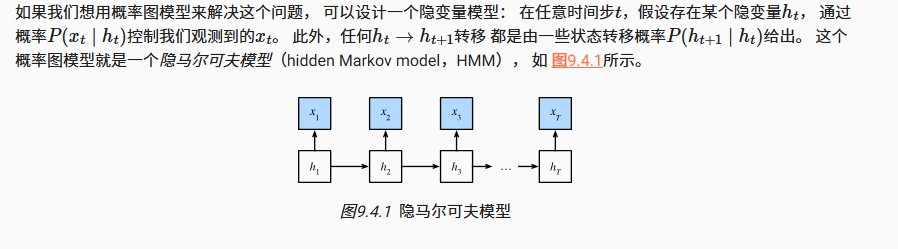
由此我们的得到的以下联合概率分布公式

这个公式的含义是,对于一个既定的对输出和隐藏状态的观测的预测概率,其实也就是按照链条相乘了所有的关系依赖项
这时候我们只考虑输出(也就是我们最终需求的部分,也是可控的部分,因为输出存在label对照,但是隐状态h显然是没有的)

在第三行的拆分中,外层的Σ符号选中的是一个状态(包含h_2 to h_T),内层的Σ则是选中所有的h_1状态并且直接做求和计算。也就是说,我们先将所有的h_1的情况打包,然后由于这些数据只会和h_2连接,于是我们在下一层在这个pai部分和h_2相关的打包,以此类推。有以下递归公式
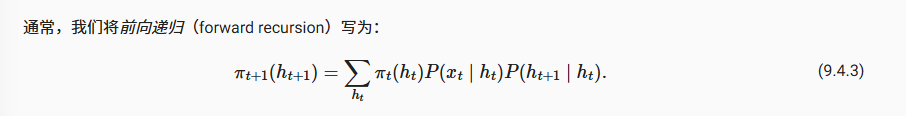
这个公式中,我们可以看出使用递归算法的时间复杂度是O(TK^2),K是一个状态的可选分布。总之,这样化简就可以是多项式内复杂度了。
这个时间复杂度的得到,我们考虑一个状态h_(t+1),首先其需要收集所有的h_t的状态求和(也就是9.4.3中的求和),其次,和这个状态等效的还有K-1个状态,所以计算到达t+1时间步的所有状态的计算次数是K^2
然后我们再来看反向的情况,也就是通过后方的观察向前预测(或者说是修正?)

事实上对于,不先入为主的观察一个列表,其两端应当被视为是等效的,所以其实从尾部进行递归的操作是完全和前向等价的,于是我们也有以下的递归公式。
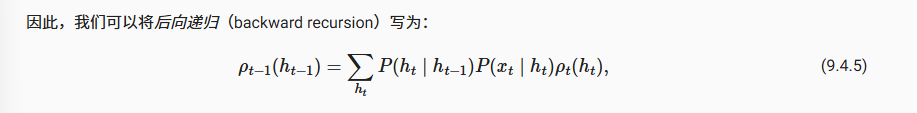
不过这里初始化第一个概率ρ为1,因为我们是反向计算的
“ 同样,这看起来非常像一个更新方程, 只是不像我们在循环神经网络中看到的那样前向运算,而是后向计算。 事实上,知道未来数据何时可用对隐马尔可夫模型是有益的。”
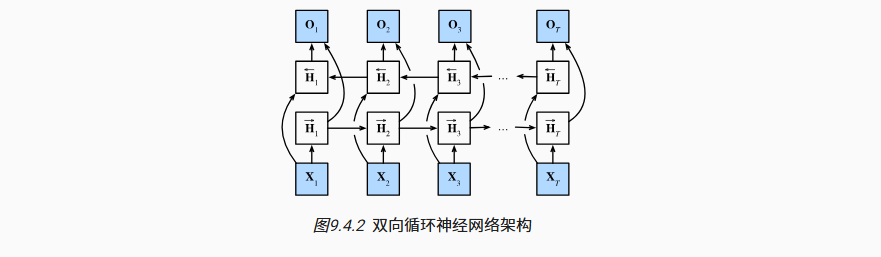

不过这里我们显然会有几个问题,例如,在实际预测的时候,我根本就不知道结束的位置在哪里,也不知道结束的单词在哪里。
事实上:对于需要“实时预测下一个词”的任务(比如现在的 ChatGPT 聊天、或者手机输入法的下一个词预测),我们绝对不能、也无法使用标准的双向 RNN。
所以说这个技术主要是用于具有完整信息下的分析任务

文中也提到
“双向层的使用在实践中非常少,并且仅仅应用于部分场合。”
- Title: Notes on Section 9.4
- Author: bobown_yao
- Created at : 2026-03-05 00:00:00
- Updated at : 2026-03-08 19:46:44
- Link: https://bobownyao.github.io/2026/03/05/Notes-on-Section-9-4/
- License: All Rights Reserved © bobown_yao