Notes on Section 9.5
本节主要讲述的是机器翻译,在机器翻译的发展史中,先后出现了统计机器翻译(SMT)和神经机器翻译(NMT)。前者主要是基于贝叶斯模型来寻找概率最高的句子,这种情境下,机器不会理解语义,而是采取最优配对的策略。而我们这一部分主要讲的是后者,也就是NMT
NMT强调的是端到端学习,也就是直接拟合原文到翻译的后验概率。
首先我们先获取一个数据集,结构是“当前语言-目标语言”的对应格式,然后预处理,分离单词和标点(这一步的粒度是字符级),然后洗完之后重组并词元化。
最后洗完的数据分布如下
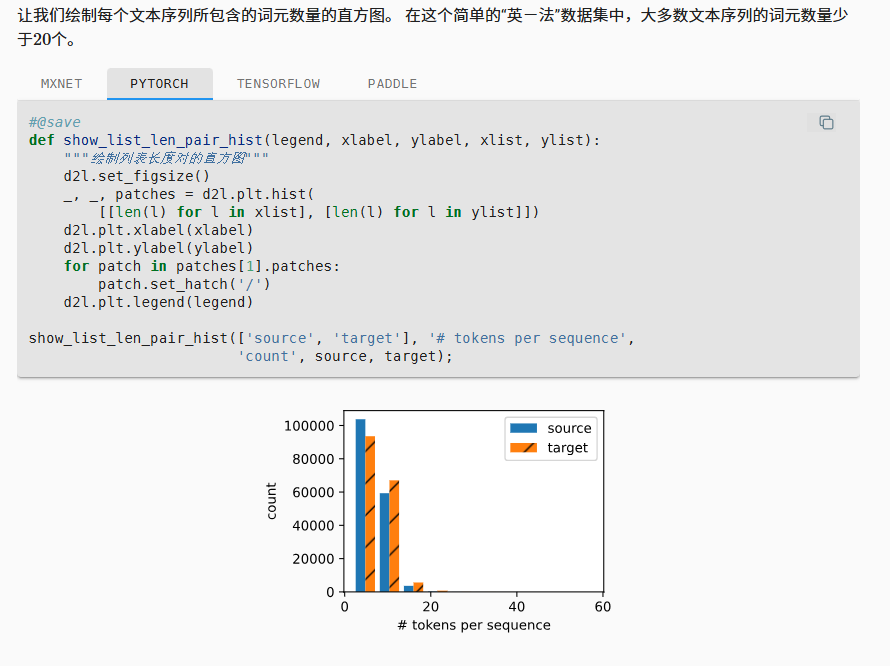
然后构建词表,增加虚拟词

然后增加一些结构和训练标签的处理
最后好像文章里没有跑模型,呃呃所以这一节其实就构建了数据集?
那好吧溜了溜了
- Title: Notes on Section 9.5
- Author: bobown_yao
- Created at : 2026-03-08 00:00:00
- Updated at : 2026-03-08 19:46:44
- Link: https://bobownyao.github.io/2026/03/08/Notes-on-Section-9-5/
- License: All Rights Reserved © bobown_yao